

 Реферат: Распределенные алгоритмы
Реферат: Распределенные алгоритмы
Заглавные буквы (C, T) используются для времени часов, а строчные буквы (c, t) - для реального времени. Часы могут использоваться для управления наступлением событий, как в выражении
when ![]() then send message
then send message
rоторое вызывает посылку сообщения во
время ![]() . Функция
. Функция ![]() обозначается
обозначается ![]() .
.
Значение идеальных часов увеличивается на ![]() за
за ![]() единиц времени, то есть,
оно удовлетворяет
единиц времени, то есть,
оно удовлетворяет ![]() .
Синхронизированные идеальные часы никогда не нуждаются в корректировке, но, к
сожалению, они всего лишь (полезная) математическая абстракция. Часы,
используемые в распределенных системах, испытывают отклонение,
ограниченное маленькой известной константой
.
Синхронизированные идеальные часы никогда не нуждаются в корректировке, но, к
сожалению, они всего лишь (полезная) математическая абстракция. Часы,
используемые в распределенных системах, испытывают отклонение,
ограниченное маленькой известной константой ![]() (обычно
порядка
(обычно
порядка ![]() или
или ![]() ). Отклонение часов C
). Отклонение часов C ![]() -ограничено, если,
для
-ограничено, если,
для ![]() и
и ![]() , таких, что между
, таких, что между ![]() и
и ![]() не происходит присваивания
C,
не происходит присваивания
C,
![]() (14.1)
(14.1)
Различные часы в распределенных системах не показывают одно
и то же время часов в любой заданный момент реального времени, то есть, ![]() не обязательно справедливо.
Часы
не обязательно справедливо.
Часы ![]() -синхронизированы в
момент реального времени t, если
-синхронизированы в
момент реального времени t, если ![]() , и
, и ![]() -синхронизированы
момент часового времени T, если
-синхронизированы
момент часового времени T, если ![]() . Мы
считаем эти понятия эквивалентными; см. Упражнение 14.8. Цель алгоритмов
синхронизации часов состоит в том, чтобы достичь и поддерживать глобальную
. Мы
считаем эти понятия эквивалентными; см. Упражнение 14.8. Цель алгоритмов
синхронизации часов состоит в том, чтобы достичь и поддерживать глобальную ![]() -синхронизацию, то есть,
-синхронизацию, то есть, ![]() -синхронизацию между каждой
парой часов. Параметр
-синхронизацию между каждой
парой часов. Параметр ![]() - точность
синхронизации.
- точность
синхронизации.
Задержка сообщений ограничена снизу ![]() и сверху
и сверху ![]() , где
, где ![]() ; формально, если сообщение
посылается в реальное время
; формально, если сообщение
посылается в реальное время ![]() и
получается в реальное время
и
получается в реальное время ![]() , то
, то
![]() (14.2)
(14.2)
Так как выбор кадра реального времени свободный, предположения (14.1) и (14.2) относятся к временному кадру так же, как и к часам и системе связи.
В этом подразделе будет изучена степень точности, с которой
процесс p может настраивать свои идеальные часы на идеальные часы надежного
сервера s. У детерминированного протокола самая лучшая доступная точность - ![]() , и эта точность может быть
получена для простого протокола, который обменивается только одним сообщением.
Вероятностные протоколы могут достигать произвольной точности, но сложность по
сообщениям зависит от желательной точности и распределения времен доставки
сообщений.
, и эта точность может быть
получена для простого протокола, который обменивается только одним сообщением.
Вероятностные протоколы могут достигать произвольной точности, но сложность по
сообщениям зависит от желательной точности и распределения времен доставки
сообщений.
Теорема 14.12
Существует детерминированный протокол для синхронизирования ![]() с
с ![]() с точностью
с точностью ![]() , который обменивается одним
сообщением. Никакой детерминированный протокол не достигает более высокой точности.
, который обменивается одним
сообщением. Никакой детерминированный протокол не достигает более высокой точности.
Доказательство. Мы сначала представим простой протокол и
докажем, что он достигает точности, заявленной в теореме. Чтобы
синхронизировать ![]() , сервер посылает
одно сообщение, <time,
, сервер посылает
одно сообщение, <time, ![]() >. Когда p получает <time, Т>, он корректирует часы на T +
>. Когда p получает <time, Т>, он корректирует часы на T + ![]() .
.
Чтобы доказать заявленную точность, назовем реальные
времена посылки и получения сообщения <time,
Т> ![]() и
и ![]() соответственно; теперь
соответственно; теперь ![]() . Так как часы идеальны,
. Так как часы идеальны, ![]() . Во время
. Во время ![]() , p корректирует часы, чтобы
на них было
, p корректирует часы, чтобы
на них было ![]() , поэтому
, поэтому ![]() . Теперь
. Теперь ![]() означает
означает ![]() .
.
 |
|||||
|
|||||
|
|||||
|
|||||
 |
|||||
|
|||||
|
|||||
|
|||||
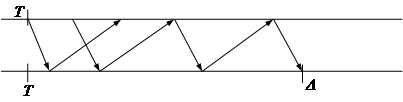
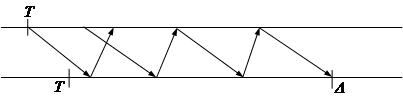
Рисунок 14.5 Сценарии для детерминированного протокола.
Чтобы показать нижнюю границу для точности, пусть дан детерминированный
протокол; в этом протоколе p и s обмениваются некоторыми сообщениями, после
которых p корректирует свои часы. Рассматриваются два сценария для протокола,
как изображено на Рисунке 14.5. В первом сценарии, часы равны до выполнения,
все сообщения из s в p доставляются после ![]() ,
и все сообщения из p в s доставляются после
,
и все сообщения из p в s доставляются после ![]() .
Если корректировка в этом сценарии -
.
Если корректировка в этом сценарии - ![]() , то часы
p в точности на
, то часы
p в точности на ![]() опережают
опережают ![]() после синхронизации.
после синхронизации.
Во втором сценарии ![]() до
выполнения отстает от
до
выполнения отстает от ![]() на
на ![]() , все сообщения из p в s
доставляются после
, все сообщения из p в s
доставляются после ![]() , и все сообщения
из s в p доставляются после
, и все сообщения
из s в p доставляются после ![]() . Назвав
корректировку в этом сценарии
. Назвав
корректировку в этом сценарии ![]() , мы
видим, что часы p после синхронизации отстают от
, мы
видим, что часы p после синхронизации отстают от ![]() в
точности на
в
точности на ![]() .
.
Однако, ни p ни s не наблюдают различия между сценариями,
так как неопределенность в задержке сообщения скрывает различие; следовательно ![]() . Это означает, что точность
самого худшего случая
. Это означает, что точность
самого худшего случая
![]()
Этот минимум равняется (и случается при ![]() ). o
). o
Если два процесса p и q синхронизируют свои часы с сервером
с этой точностью, достигается глобальная ![]() -синхронизация,
который достаточно для большинства прикладных программ.
-синхронизация,
который достаточно для большинства прикладных программ.
Лучшая точность достижима у вероятностного протокола синхронизации,
предложенного Кристианом [Cri89]. Для этого протокола принимается, что задержка
сообщения - стохастическая переменная, распределенная согласно (не обязательно
известной) функции ![]() . Вероятность
прибытия любого сообщения в течение x - F(x), и задержки различных
сообщений независимы. Произвольная точность достижима только если нижняя
граница
. Вероятность
прибытия любого сообщения в течение x - F(x), и задержки различных
сообщений независимы. Произвольная точность достижима только если нижняя
граница ![]() плотна, то есть, для всех
x>
плотна, то есть, для всех
x>![]() , F (x) > 0.
, F (x) > 0.
Протокол прост; p просит, чтобы s послал время, и s
немедленно отвечает сообщением <time, T>.
Процесс p измеряет время I между посылкой запроса и получения
ответа; справедливо ![]() . Задержка сообщения
ответа - по крайней мере
. Задержка сообщения
ответа - по крайней мере ![]() и самое
большее
и самое
большее ![]() , и следовательно отличается
самое большее на
, и следовательно отличается
самое большее на ![]() от
от ![]() . Таким образом, p может
установить свои часы в
. Таким образом, p может
установить свои часы в ![]() , и достигает
точности
, и достигает
точности ![]() . Если желательная точность
-
. Если желательная точность
- ![]() , p посылает новый запрос
если
, p посылает новый запрос
если ![]() , в противном случае
завершается.
, в противном случае
завершается.
Лемма 14.13
Вероятностный протокол синхронизации часов достигает точности ![]() с ожидаемым числом сообщений
самое большее
с ожидаемым числом сообщений
самое большее ![]() .
.
Доказательство. Вероятность того, что запрос p прибывает в
течение ![]() -
- ![]() и такова же вероятность
того, что ответ прибывает внутри в течение
и такова же вероятность
того, что ответ прибывает внутри в течение ![]() .
Следовательно, вероятность того, что p получает ответ в течение
.
Следовательно, вероятность того, что p получает ответ в течение ![]() - по крайней мере
- по крайней мере ![]() , что означает границу в
, что означает границу в ![]() на ожидаемое число
испытаний до успешного обмена сообщениями. o
на ожидаемое число
испытаний до успешного обмена сообщениями. o
Временная сложность протокола уменьшается, если p посылает
новый запрос когда никакого ответа не было получено ![]() после
посылки запроса. Ожидаемое время тогда не зависит от ожидаемой или максимальной
задержки, а именно
после
посылки запроса. Ожидаемое время тогда не зависит от ожидаемой или максимальной
задержки, а именно ![]() , и протокол
устойчив против потери сообщений. (Нужно использовать номера в порядке
следования, чтобы отличить устаревшие ответы.)
, и протокол
устойчив против потери сообщений. (Нужно использовать номера в порядке
следования, чтобы отличить устаревшие ответы.)
14.3.2 Распределенная Синхронизация Часов
Этот раздел представляет t-Византийско-устойчивый (при t <
N/3) распределенный алгоритм синхронизации часов Махани и Шнайдера [MS85].
Долев, Халперн и Стронг [DHS84] показали, что никакая синхронизация не возможна
при ![]() , если не используется
установление подлинности.
, если не используется
установление подлинности.
Ядро алгоритма синхронизации - протокол, который достигает неточного
соглашения о средних значениях часов. Процессы корректируют свои часы и достигают
высокой степени синхронизации. Из-за отклонения через некоторое время точность
ухудшается, что влечет за собой новый раунд синхронизации после некоторого
интервала. Предположим, что в реальное время ![]() часы
часы
![]() -синхронизированы; тогда до
времени
-синхронизированы; тогда до
времени ![]() часы
часы ![]() -синхронизированы. Таким
образом, если желательная точность -
-синхронизированы. Таким
образом, если желательная точность - ![]() , и раунд
синхронизации достигает точности
, и раунд
синхронизации достигает точности ![]() , раунды
повторяются каждые
, раунды
повторяются каждые ![]() единиц времени.
Так как время, допустим S, для выполнения раунда синхронизации обычно очень
мало по сравнению с R, то оправдано упрощающее предположение о том, что в
течение синхронизации отклонением можно пренебречь, то есть, часы являются
идеальными.
единиц времени.
Так как время, допустим S, для выполнения раунда синхронизации обычно очень
мало по сравнению с R, то оправдано упрощающее предположение о том, что в
течение синхронизации отклонением можно пренебречь, то есть, часы являются
идеальными.
Неточное соглашение: алгоритм с быстрой сходимостью. В
проблеме неточного соглашения, используемой Махани и Шнайдером [MS85] для
синхронизации часов, процесс p имеет действительное входное значение ![]() , где для корректных p и q
, где для корректных p и q ![]() . Выход процесса p -
действительное значение
. Выход процесса p -
действительное значение ![]() , и точность
выхода определяется как
, и точность
выхода определяется как ![]() ; цель
алгоритма состоит в том, чтобы достичь очень малого значения точности.
; цель
алгоритма состоит в том, чтобы достичь очень малого значения точности.
var ![]() ,
, ![]() ,
, ![]() : real; (*Вход,
выход, оценщик V *)
: real; (*Вход,
выход, оценщик V *)
![]() ,
,
![]() :
multiset of real;
:
multiset of real;
begin (*фаза сбора входов*)
![]()
forall ![]() do send <ask>
to q
do send <ask>
to q
wait ![]() ; (*Обработать
сообщения <ask> и <val, x>*)
; (*Обработать
сообщения <ask> и <val, x>*)
while ![]() do insert (
do insert (![]() );
);
(*Теперь вычислить приемлемые значения*)
![]()
![]()
while ![]() do insert(
do insert(![]() ,
, ![]() );
);
![]()
end
После получения <ask> от q:
send<val, ![]() > to q
> to q
После получения <val, x> от q:
if такое сообщение не было получено от q прежде
then insert(![]() , x)
, x)
Алгоритм 14.6 алгоритм с быстрой сходимостью.
Алгоритм с быстрой сходимостью, предложенный Махани и
Шнайдером дан как Алгоритм 14.6. Для конечного множества ![]() , определим две функции intvl(A)=[min(A), max(A)]
и width(A) = max(A) - min(A). Алгоритм имеет фазу сбора входов и фазу
вычисления. В первой фазе процесс p просит каждый другой процесс послать свой
вход (“выкрикивая” сообщение <ask>) и ждет
, определим две функции intvl(A)=[min(A), max(A)]
и width(A) = max(A) - min(A). Алгоритм имеет фазу сбора входов и фазу
вычисления. В первой фазе процесс p просит каждый другой процесс послать свой
вход (“выкрикивая” сообщение <ask>) и ждет
![]() единиц времени. После этого
времени, p получил все входы от корректных процессов, также как и ответы от
подмножества сбойных процессов. Эти ответы заполняются (бессмысленными)
значениями
единиц времени. После этого
времени, p получил все входы от корректных процессов, также как и ответы от
подмножества сбойных процессов. Эти ответы заполняются (бессмысленными)
значениями ![]() для процессов, которые не
ответили.
для процессов, которые не
ответили.
Затем процесс применяет к полученным значениям фильтр,
который гарантированно пропускает все значения корректных процессов и только те
сбойные значения, которые достаточно близки к правильным значениям. Поскольку
корректные значения отличаются только на ![]() и
имеется по крайней мере N-t корректных значений, каждое
корректное значение имеет по крайней мере N-t значения,
которые отличаются самое большее на
и
имеется по крайней мере N-t корректных значений, каждое
корректное значение имеет по крайней мере N-t значения,
которые отличаются самое большее на ![]() от него;
от него;
![]() сохраняет полученные
значения с этим свойством.
сохраняет полученные
значения с этим свойством.
Затем вычисляется выход с помощью усреднения значений - все
отклоненные значения заменяются оценкой, вычисленной применением
детерминированной функции estimator к оставшимся значениям. Эта функция
удовлетворяет ![]() , но в остальном
произвольна; она может быть минимумом, максимумом, средним, или
, но в остальном
произвольна; она может быть минимумом, максимумом, средним, или ![]() .
.
Теорема 14.14
Алгоритм с быстрой сходимостью достигает точности ![]() .
.
Доказательство. Пусть ![]() -
значение, включаемое в
-
значение, включаемое в ![]() для процесса r,
когда p превышает лимит времени (то есть,
для процесса r,
когда p превышает лимит времени (то есть, ![]() -
или
-
или ![]() или
или ![]() ), и
), и ![]() - значение в
- значение в ![]() для процесса r, когда p
вычисляет
для процесса r, когда p
вычисляет ![]() (То есть
(То есть ![]() - или
- или ![]() или
или ![]() ). Точность будет ограничена
разделением суммирования в вычислении решения на суммирование над корректными
процессами (C) и некорректными процессами (B). Для корректных p и q, разность
). Точность будет ограничена
разделением суммирования в вычислении решения на суммирование над корректными
процессами (C) и некорректными процессами (B). Для корректных p и q, разность ![]() ограничена 0, если
ограничена 0, если ![]() , и
, и ![]() если
если ![]() .
.
Первая граница следует из того, что, так как если p и r -
корректные процессы, то ![]() .
Действительно, так как r отвечает на сообщение p <ask>
быстро,
.
Действительно, так как r отвечает на сообщение p <ask>
быстро, ![]() . Точно так же
. Точно так же ![]() для всех корректных r', и
предположение о входе означает, что значение r переживает фильтрацию процессом
p, следовательно Учреждение, несущее основную ответственность
для всех корректных r', и
предположение о входе означает, что значение r переживает фильтрацию процессом
p, следовательно Учреждение, несущее основную ответственность ![]() .
.
Вторая граница справедлива, так как для корректных p и q, ![]() , когда p и q вычисляют свои
решения. Так как добавленные оценки находятся между принятыми значениями,
достаточно рассмотреть максимальное различие между значениями
, когда p и q вычисляют свои
решения. Так как добавленные оценки находятся между принятыми значениями,
достаточно рассмотреть максимальное различие между значениями ![]() и
и ![]() , которые прошли фильтры p и
q соответственно. Имеется по крайней мере N-t процессов
r, для которых
, которые прошли фильтры p и
q соответственно. Имеется по крайней мере N-t процессов
r, для которых ![]() , и по крайней
мере N-t процессов r, для которых
, и по крайней
мере N-t процессов r, для которых ![]() . Это означает, что имеется корректный
r такой, что
. Это означает, что имеется корректный
r такой, что ![]() и
и ![]() ; но так как r корректен,
; но так как r корректен, ![]() , следовательно
, следовательно ![]() .
.
Отсюда следует, что для корректных p и q,
![]() =
=
![]()
= 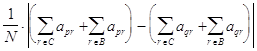
= 
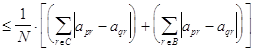
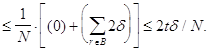
o
Произвольная точность может быть достигнута повторением
алгоритма; после i итераций, точность становится ![]() .
Точность даже лучше, если меньшая доля (чем треть) процессов сбойная; в выводе
точности t можно понимать как фактическое число сбойных процессов. Выходную
точность алгоритма (самую худшую) нельзя улучшить подходящим выбором функции estimator;
действительно, Византийский процесс r может навязать p любое значение
.
Точность даже лучше, если меньшая доля (чем треть) процессов сбойная; в выводе
точности t можно понимать как фактическое число сбойных процессов. Выходную
точность алгоритма (самую худшую) нельзя улучшить подходящим выбором функции estimator;
действительно, Византийский процесс r может навязать p любое значение ![]() , просто посылая p это
значение. Функция может быть выбрана соответственно, чтобы достигнуть хорошей
средней точности, когда известно что-нибудь о наиболее вероятном поведении
сбойных процессов.
, просто посылая p это
значение. Функция может быть выбрана соответственно, чтобы достигнуть хорошей
средней точности, когда известно что-нибудь о наиболее вероятном поведении
сбойных процессов.
Синхронизация Часов. Чтобы синхронизировать часы,
используется алгоритм с быстрой сходимостью, чтобы достигнуть неточного
соглашения по новому значению часов. Предполагается, что часы первоначально ![]() синхронизированы. Алгоритм
должен быть адаптирован, так как
синхронизированы. Алгоритм
должен быть адаптирован, так как
(1) Задержка сообщения точно не известна, так что процесс не может знать точное значение другого процесса; и
(2) При выполнении алгоритма идет время, так что часы не имеют постоянных значения, а увеличиваются со временем.
Чтобы компенсировать неизвестную задержку, процесс добавляет ![]() к получаемым значениям
часов (как в детерминированном протоколе Теоремы 14.12), вводя дополнительное
слагаемое
к получаемым значениям
часов (как в детерминированном протоколе Теоремы 14.12), вводя дополнительное
слагаемое ![]() в выходную точность. Чтобы
представлять полученное значение как значение часов, а не как константу, p
хранит разность полученного значения часов (плюс
в выходную точность. Чтобы
представлять полученное значение как значение часов, а не как константу, p
хранит разность полученного значения часов (плюс ![]() )
и собственного как
)
и собственного как ![]() . Во время t,
приближение часов r процессом p -
. Во время t,
приближение часов r процессом p - ![]() . Измененный алгоритм дан
как Алгоритм 14.7.
. Измененный алгоритм дан
как Алгоритм 14.7.
var ![]() ,
, ![]() ,
, ![]() : real; (*Вход,
адаптация, оценщик V *)
: real; (*Вход,
адаптация, оценщик V *)
![]() ,
,
![]() :
multiset of real;
:
multiset of real;
begin (*фаза сбора входов*)
![]()
forall ![]() do send <ask>
to q
do send <ask>
to q
wait ![]() ; (*Обработать
сообщения <ask> и <val, x>*)
; (*Обработать
сообщения <ask> и <val, x>*)
while ![]() do insert (
do insert (![]() );
);
(*Теперь вычислить приемлемые значения*)
![]()
![]()
while ![]() do insert(
do insert(![]() ,
, ![]() );
);
![]()
![]()
end
После получения <ask> от q:
send<val, ![]() > to q
> to q
После получения <val, С> от q:
if такое сообщение не было получено от q прежде
then ![]()
Алгоритм 14.7 быстрая сходимость часов.
Заметьте, что в Алгоритме 14.7 фильтр имеет более широкую
грань, а именно ![]() , чем в Алгоритме
14.6, где грань
, чем в Алгоритме
14.6, где грань ![]() . Более широкая
грань компенсирует неизвестную задержку сообщения, и порог возникает из
следующего утверждения. Пусть
. Более широкая
грань компенсирует неизвестную задержку сообщения, и порог возникает из
следующего утверждения. Пусть ![]() обозначает
значение, которое p вставил в
обозначает
значение, которое p вставил в ![]() для процесса
r после первой фазы p (сравните со значением
для процесса
r после первой фазы p (сравните со значением ![]() в
предыдущем алгоритме).
в
предыдущем алгоритме).
Утверждение 14.15
Для корректных p, q, и r, после лимита времени p выполняется ![]() .
.
Доказательство. Передача сообщения <val,
C> от q до p осуществляет детерминированный алгоритм чтения часов из
Теоремы 14.12. Когда p получает это сообщение, ![]() ограничено
ограничено
![]() , поэтому
, поэтому ![]() отличается самое большее на
отличается самое большее на
![]() от
от ![]() . Точно так же
. Точно так же ![]() отличается
отличается
[1] - функция Эйлера “фи”; - размер
