

 Дипломная работа: Моделирование сети кластеризации данных в MATLAB NEURAL NETWORK TOOL
Дипломная работа: Моделирование сети кластеризации данных в MATLAB NEURAL NETWORK TOOL
3.1.2 Создание сети
Для формирования слоя Кохонена предназначена М-функция newc. Покажем, как она работает, на простом примере. Предположим, что задан массив из четырех двухэлементных векторов, которые надо разделить на 2 класса:
р = [.1 .8 .1 .9; .2 .9 .1 .8]
р =
0.1000 0.8000 0.1000 0.9000
0.2000 0.9000 0.1000 0.8000.
В этом примере нетрудно видеть, что 2 вектора расположены вблизи точки (0,0) и 2 вектора - вблизи точки (1,1). Сформируем слой Кохонена с двумя нейронами для анализа двухэлементных векторов входа с диапазоном значений от 0 до 1:
net = newc([0 1; 0 1],2).
Первый аргумент указывает диапазон входных значений, второй определяет количество нейронов в слое. Начальные значения элементов матрицы весов задаются как среднее максимального и минимального значений, т. е. в центре интервала входных значений; это реализуется по умолчанию с помощью М-функции midpoint при создании сети. Убедимся, что это действительно так:
wts = net.IW{l,l}
wts =
0.5000 0.5000
0.5000 0.5000.
Определим характеристики слоя Кохонена:
net.layers{1}
ans =
dimensions: 2
distanсeFcn: 'dist'
distances:[2x2 double]
initFcn:' initwb '
netinputFcn:'netsum'
positions:[0 1]
size:2
topologyFcn:'hextop'
transferFcn:'compet'
userdata:[1x1 struct].
Из этого описания следует, что сеть использует функцию евклидова расстояния dist, функцию инициализации initwb, функцию обработки входов netsum, функцию активации compet и функцию описания топологии hextop.
Характеристики смещений следующие:
net.biases{1}
ans =
initFcn:'initcon'
learn:1
learnFcn:'learncon'
learnParam:[1x1 struct]
size:2
userdata:[1x1 struct].
Смещения задаются функцией initcon и для инициализированной сети равны
net.b{l}
ans =
5.4366
5.4366.
Функцией настройки смещений является функция lеаrcon, обеспечивающая настройку с учетом параметра активности нейронов.
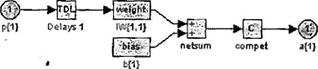
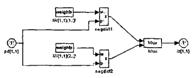
Элементы структурной схемы слоя Кохонена показаны на рисунке 3.2, а-б и могут быть получены с помощью оператора:
gensim(net)
Они наглядно поясняют архитектуру и функции, используемые при построении слоя Кохонена.
Теперь, когда сформирована самоорганизующаяся
нейронная сеть, требуется обучить сеть решению задачи кластеризации данных.
Напомним, что каждый нейрон блока compet конкурирует за право ответить на
вектор входа ![]() . Если все смещения равны 0, то
нейрон с вектором веса, самым близким к вектору входа
. Если все смещения равны 0, то
нейрон с вектором веса, самым близким к вектору входа ![]() , выигрывает конкуренцию и
возвращает на выходе значение 1; все другие нейроны возвращают значение 0.
, выигрывает конкуренцию и
возвращает на выходе значение 1; все другие нейроны возвращают значение 0.
а б
Рисунок 3.2 – Элементы структурной схемы слоя Кохонена
3.1.3 Правило обучения слоя Кохонена
Правило обучения слоя Кохонена, называемое также
правилом Кохонена, заключается в том, чтобы настроить нужным образом элементы
матрицы весов. Предположим, что нейрон ![]() победил при подаче входа
победил при подаче входа ![]() на шаге
самообучения
на шаге
самообучения ![]() , тогда строка
, тогда строка ![]() матрицы весов
корректируется в соответствии с правилом Кохонена следующим образом:
матрицы весов
корректируется в соответствии с правилом Кохонена следующим образом:
![]() . (3.2)
. (3.2)
Правило Кохонена представляет собой рекуррентное
соотношение, которое обеспечивает коррекцию строки ![]() матрицы весов добавлением
взвешенной разности вектора входа и значения строки на предыдущем шаге. Таким
образом, вектор веса, наиболее близкий к вектору входа, модифицируется так,
чтобы расстояние между ними стало еще меньше. Результат такого обучения будет
заключаться в том, что победивший нейрон, вероятно, выиграет конкуренцию и в
том случае, когда будет представлен новый входной вектор, близкий к
предыдущему, и его победа менее вероятна, когда будет представлен вектор,
существенно отличающийся от предыдущего. Когда на вход сети поступает все
большее и большее число векторов, нейрон, являющийся ближайшим, снова
корректирует свой весовой вектор. В конечном счете, если в слое имеется
достаточное количество нейронов, то каждая группа близких векторов окажется
связанной с одним из нейронов слоем. В этом и заключается свойство
самоорганизации слоя Кохонена.
матрицы весов добавлением
взвешенной разности вектора входа и значения строки на предыдущем шаге. Таким
образом, вектор веса, наиболее близкий к вектору входа, модифицируется так,
чтобы расстояние между ними стало еще меньше. Результат такого обучения будет
заключаться в том, что победивший нейрон, вероятно, выиграет конкуренцию и в
том случае, когда будет представлен новый входной вектор, близкий к
предыдущему, и его победа менее вероятна, когда будет представлен вектор,
существенно отличающийся от предыдущего. Когда на вход сети поступает все
большее и большее число векторов, нейрон, являющийся ближайшим, снова
корректирует свой весовой вектор. В конечном счете, если в слое имеется
достаточное количество нейронов, то каждая группа близких векторов окажется
связанной с одним из нейронов слоем. В этом и заключается свойство
самоорганизации слоя Кохонена.
Настройка параметров сети по правилу Кохонена реализована в виде М-функции learnk.
3.1.4 Правило настройки смещений
Одно из ограничений всякого конкурирующего слоя состоит в том, что некоторые нейроны оказываются незадействованными. Это проявляется в том, что нейроны, имеющие начальные весовые векторы, значительно удаленные от векторов входа, никогда не выигрывают конкуренции, независимо от того как долго продолжается обучение. В результате оказывается, что такие векторы не используются при обучении и соответствующие нейроны никогда не оказываются победителями. Такие нейроны-неудачники называются "мертвыми" нейронами, поскольку они не выполняют никакой полезной функции. Чтобы исключить такую ситуацию и сделать нейроны чувствительными к поступающим на вход векторам, используются смещения, которые позволяют нейрону стать конкурентным с нейронами-победителями. Этому способствует положительное смещение, которое добавляется к отрицательному расстоянию удаленного нейрона.
Соответствующее правило настройки, учитывающее нечувствительность мертвых нейронов, реализовано в виде М-функции learncon и заключается в следующем - в начале процедуры настройки всем нейронам конкурирующего слоя присваивается одинаковый параметр активности:
 , (3.3)
, (3.3)
где ![]() - количество нейронов
конкурирующего слоя, равное числу кластеров. В процессе настройки М-функция
learncon корректирует этот параметр таким образом, чтобы его значения для
активных нейронов становились больше, а для неактивных нейронов меньше.
Соответствующая формула для вектора приращений параметров активности выглядит
следующим образом:
- количество нейронов
конкурирующего слоя, равное числу кластеров. В процессе настройки М-функция
learncon корректирует этот параметр таким образом, чтобы его значения для
активных нейронов становились больше, а для неактивных нейронов меньше.
Соответствующая формула для вектора приращений параметров активности выглядит
следующим образом:
![]() , (3.4)
, (3.4)
где ![]() - параметр скорости настройки;
- параметр скорости настройки; ![]() -вектор,
элемент
-вектор,
элемент ![]() которого
равен 1, а остальные - 0.
которого
равен 1, а остальные - 0.
Нетрудно убедиться, что для всех нейронов, кроме нейрона-победителя, приращения отрицательны. Поскольку параметры активности связаны со смещениями соотношением (в обозначениях системы MATLAB):
![]() , (3.5)
, (3.5)
то из этого следует, что смещение для нейрона-победителя уменьшится, а смещения для остальных нейронов немного увеличатся.
М-функция learnсon использует следующую формулу для расчета приращений вектора смещений:
![]() . (3.6)
. (3.6)
Параметр скорости настройки ![]() по умолчанию равен 0.001, и его
величина обычно на порядок меньше соответствующего значения для М-функции
learnk. Увеличение смещений для неактивных нейронов позволяет расширить
диапазон покрытия входных значений, и неактивный нейрон начинает формировать
кластер. В конечном счете он может начать притягивать новые входные векторы -
это дает два преимущества. Первое преимущество, если нейрон не выигрывает
конкуренции, потому что его вектор весов существенно отличается от векторов,
поступающих на вход сети, то его смещение по мере обучения становится
достаточно большим и он становится конкурентоспособным. Когда это происходит,
его вектор весов начинает приближаться к некоторой группе векторов входа. Как
только нейрон начинает побеждать, его смещение начинает уменьшаться. Таким
образом, задача активизации "мертвых" нейронов оказывается решенной.
Второе преимущество, связанное с настройкой смещений, состоит в том, что они позволяют
выровнять значения параметра активности и обеспечить притяжение приблизительно
одинакового количества векторов входа. Таким образом, если один из кластеров
притягивает большее число векторов входа, чем другой, то более заполненная
область притянет дополнительное количество нейронов и будет поделена на меньшие
по размерам кластеры.
по умолчанию равен 0.001, и его
величина обычно на порядок меньше соответствующего значения для М-функции
learnk. Увеличение смещений для неактивных нейронов позволяет расширить
диапазон покрытия входных значений, и неактивный нейрон начинает формировать
кластер. В конечном счете он может начать притягивать новые входные векторы -
это дает два преимущества. Первое преимущество, если нейрон не выигрывает
конкуренции, потому что его вектор весов существенно отличается от векторов,
поступающих на вход сети, то его смещение по мере обучения становится
достаточно большим и он становится конкурентоспособным. Когда это происходит,
его вектор весов начинает приближаться к некоторой группе векторов входа. Как
только нейрон начинает побеждать, его смещение начинает уменьшаться. Таким
образом, задача активизации "мертвых" нейронов оказывается решенной.
Второе преимущество, связанное с настройкой смещений, состоит в том, что они позволяют
выровнять значения параметра активности и обеспечить притяжение приблизительно
одинакового количества векторов входа. Таким образом, если один из кластеров
притягивает большее число векторов входа, чем другой, то более заполненная
область притянет дополнительное количество нейронов и будет поделена на меньшие
по размерам кластеры.
3.1.5 Обучение сети
Реализуем 10 циклов обучения. Для этого можно использовать функции train или adapt:
net.trainParam.epochs = 10
net = train(net,p)
net.adaptParam.passes = 10
[net,y,e] = adapt(net,mat2cell(p)).
Заметим, что для сетей с конкурирующим слоем по умолчанию используется обучающая функция trainwbl, которая на каждом цикле обучения случайно выбирает входной вектор и предъявляет его сети; после этого производится коррекция весов и смещений.
Выполним моделирование сети после обучения:
а = sim(net,p)
ас = vec2ind(a)
ас = 2 1 2 1.
Видим, что сеть обучена классификации векторов входа на 2 кластера: первый расположен в окрестности вектора (0,0), второй - в окрестности вектора (1,1). Результирующие веса и смещения равны:
wtsl = net.IW{l,l}
b1 = net.b{l}
wts1 =
0.58383 0.58307
0.41712 0.42789
b1=
5.4152
5.4581.
Заметим, что первая строка весовой матрицы действительно близка к вектору (1,1), в то время как вторая строка близка к началу координат. Таким образом, сформированная сеть обучена классификации входов. В процессе обучения каждый нейрон в слое, весовой вектор которого близок к группе векторов входа, становится определяющим для этой группы векторов. В конечном счете, если имеется достаточное число нейронов, каждая группа векторов входа будет иметь нейрон, который выводит 1, когда представлен вектор этой группы, и 0 в противном случае, или, иными словами, формируется кластер. Таким образом, слой Кохонена действительно решает задачу кластеризации векторов входа.
3.1.6 Моделирование кластеризации данных
Функционирование слоя Кохонена можно пояснить более наглядно, используя графику системы MATLAB. Рассмотрим 48 случайных векторов на плоскости, формирующих 8 кластеров, группирующихся около своих центров. На графике, приведенном на рисунке 3.3, показано 48 двухэлементных векторов входа.
Сформируем координаты случайных точек и построим план их расположения на плоскости:
с = 8
n = 6 % Число кластеров, векторов в кластере
d = 0.5 % Среднеквадратичное отклонение от центра кластера
х = [-10 10;-5 5] % Диапазон входных значений
[r,q] = size(x); minv = min(x1)1; maxv = mах(х1)1
v = rand(r, e).С{maxv - minv) *ones(l,c) + xninv*ones (l,c) )t = c*n % Число точек
v= [v v v v v]; v=v+randn{r,t)*d % Координаты точек
Р = v
plot(P(l,:), P(2,:),'+k') % (рисунок 3.3)
title('Векторы входа'), xlabel('Р(1,:)'), ylabel('P(2,:)').
Векторы входа, показанные на рисунке 3.3, относятся к различным классам.
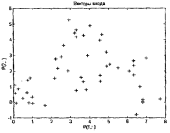
Рисунок 3.3 – Двухэлементные векторы входа
Применим конкурирующую сеть из восьми нейронов для того, чтобы распределить их по классам:
net = newc([-2 12;-1 6], 8 ,0.1)
w0 =net.IW{l}
b0 = net.b{l}
c0 = exp(l)./b0.
Начальные значения весов, смещений и параметров активности нейронов представлены ниже:
w0 =b0 =с0 =
0.50.2521.7460.125
0.50.2521,7460.125
0.50.2521.7460.125
0-50.2521.7460.125
0.50.2521.7460.125
0.50.2521.7460.125
0.50.2521.7460.125
0.50.2521.7460.125.
После обучения в течение 500 циклов получим:
net.trainParam.epochs = 500
net = train(net,P)
w = net.IW{l} bn = net.b{l}
cn = exp(1)./bn
wn=bn=cn=
6.2184 2.423922.1370,123
1.3277 0.9470121.7180.125
0.31139 0.4093521.1920.128
3.543 4.584521.4720.127
3.4617 2.8S9621.9570.124
4 3171 1.427821.1850.128
6.7065 0.4369623.0060.118
0.97S17 0.1724221.420.127.
Как следует из приведенных таблиц, центры кластеризации распределились по восьми областям, показанным на рисунке 3.4, а; смещения отклонились в обе стороны от исходного значения 21.746 также, как и параметры активности нейронов, показанные на рисунке 3.4, б.
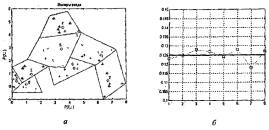
Рисунок 3.4 – Полученные центры кластеризации
Рассмотренная самонастраивающаяся сеть Кохонена является типичным примером сети, которая реализует процедуру обучения без учителя.
3.2 Карта Кохонена в MATLAB NNT
Самоорганизующаяся сеть в виде карты Кохонена предназначена для решения задач кластеризации входных векторов. В отличие от слоя Коконена карта Кохонена поддерживает такое топологическое свойство, когда близким кластерам входных векторов соответствуют близко расположенные нейроны.
Первоначальная топология размещения нейронов в слое Кохонена задается М-функциями gridtop, hextop или randtop, что соответствует размещению нейронов в узлах либо прямоугольной, либо гексагональной сетки, либо в узлах сетки со случайной топологией. Расстояния между нейронами вычисляются с помощью специальных функций вычисления расстояний dist, boxdist, linkdist и mandist.
Карта Кохонена для определения нейрона-победителя использует ту же процедуру, какая применяется и в слое Кохонена. Однако на карте Кохонена одновременно изменяются весовые коэффициенты соседних нейронов в соответствии со следующим соотношением:
![]() . (3.7)
. (3.7)
В этом случае окрестность нейрона-победителя включает
все нейроны, которые находятся в пределах некоторого радиуса ![]() :
:
![]() . (3.8)
. (3.8)
Чтобы пояснить понятие окрестности нейрона, обратимся к рисунку 3.5.
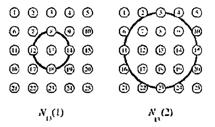
Рисунок 3.5 – Окрестности нейрона
Левая часть рисунка соответствует окрестности радиуса 1 для нейрона-победителя с номером 13; правая часть - окрестности радиуса 2 для того же нейрона. Описания этих окрестностей выглядят следующим образом:
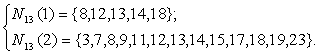
Заметим, что топология карты расположения нейронов не обязательно должна быть двумерной. Это могут быть и одномерные и трехмерные карты, и даже карты больших размерностей. В случае одномерной карты Кохонена, когда нейроны расположены вдоль линии, каждый нейрон будет иметь только двух соседей в пределах радиуса 1 или единственного соседа, если нейрон расположен на конце линии. Расстояния между нейронами можно определять различными способами, используя прямоугольные или гексагональные сетки, однако это никак не влияет на характеристики сети, связанные с классификацией входных векторов.
3.2.1 Топология карты
Как уже отмечалось выше, можно задать различные топологии для карты расположения нейронов, используя М-функции gridtop, hextop, randtop.
Рассмотрим простейшую прямоугольную сетку размера 2x3 для размещения шести нейронов, которая может быть сформирована с помощью функции gridtop:
pos = gridtop(2,3)
pos =
0 1 0 1 0 1
0 0 1 1 2 2
plotsom(pos) % (рисунок 3.6).
Соответствующая сетка показана на рисунке 3.6. Метки position(1, i) и position(2,i) вдоль координатных осей генерируются функцией plotsom и задают позиции расположения нейронов по первой, второй и т. д. размерностям карты.

Рисунок 3.6 – Прямоугольная сетка
Здесь нейрон 1 расположен в точке с координатами (0,0), нейрон 2 - в точке (1,0), нейрон 3 - в точке (0,1) и т. д. Заметим, что, если применить команду gridtop, переставив аргументы местами, получим иное размещение нейронов;
pos=gridtop(3,2)pos =
0 1 2 0 1 2
0 0 0 1 1 1.
Гексагональную сетку можно сформировать с помощью функции hextop:
