

 Дипломная работа: Моделирование сети кластеризации данных в MATLAB NEURAL NETWORK TOOL
Дипломная работа: Моделирование сети кластеризации данных в MATLAB NEURAL NETWORK TOOL
1.3.4 Метод ближайшего соседа
Этот метод является одним из старейших методов кластеризации. Он был создан в 1978 году. Он прост и наименее оптимален из всех представленных.
Для каждого объекта вне кластера делаем следующее:
1. Находим его ближайшего соседа, кластер которого определен.
2. Если расстояние до этого соседа меньше порога, то относим его в тот же кластер. Иначе из рассматриваемого объекта создается еще один кластер.
Далее рассматривается результат и при необходимости увеличивается порог, например, если много кластеров из одного объекта.
1.3.5 Алгоритм нечеткой кластеризации
Четкая (непересекающаяся) кластеризация –
кластеризация, которая каждый ![]() из
из ![]() относит только к одному кластеру.
относит только к одному кластеру.
Нечеткая кластеризация – кластеризация, при которой
для каждого ![]() из
из
![]() определяется
определяется
![]() .
. ![]() – вещественное
значение, показывающее степень принадлежности
– вещественное
значение, показывающее степень принадлежности ![]() к кластеру j.
к кластеру j.
Алгоритм нечеткой кластеризации таков:
1. Выбрать начальное нечеткое разбиение объектов на n
кластеров путем выбора матрицы принадлежности ![]() размера
размера ![]() . Обычно
. Обычно ![]() .
.
2. Используя матрицу U, найти значение критерия нечеткой ошибки. Например,
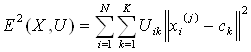 , (1.2)
, (1.2)
где ![]() - «центр масс» нечеткого кластера k,
- «центр масс» нечеткого кластера k,
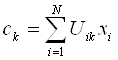 . (1.3)
. (1.3)
3. Перегруппировать объекты с целью уменьшения этого значения критерия нечеткой ошибки.
4. Возвращаться в пункт 2 до тех пор, пока изменения
матрицы ![]() не
станут значительными.
не
станут значительными.
Рисунок 1.10 – Пример алгоритма нечеткой кластеризации
1.3.6 Применение нейронных сетей
Порой для решения задач кластеризации целесообразно использовать нейронные сети. У данного подхода есть ряд особенностей:
· искусственные нейронные сети легко работают в распределенных системах с большой параллелизацией в силу своей природы;
· поскольку искусственные нейронные сети подстраивают свои весовые коэффициенты, основываясь на исходных данных, это помогает сделать выбор значимых характеристик менее субъективным.
Существует масса ИНС, например, персептрон, радиально-базисные сети, LVQ-сети, самоорганизующиеся карты Кохонена, которые можно использовать для решения задачи кластеризации. Но наиболее лучше себя зарекомендовала сеть с применением самоорганизующихся карт Кохонена, которая и выбрана для рассмотрения в данном дипломном проекте.
1.3.7 Генетические алгоритмы
Это алгоритм, используемый для решения задач оптимизации и моделирования путём случайного подбора, комбинирования и вариации искомых параметров с использованием механизмов, напоминающих биологическую эволюцию. Является разновидностью эволюционных вычислений. Отличительной особенностью генетического алгоритма является акцент на использование оператора «скрещивания», который производит операцию рекомбинации решений-кандидатов, роль которой аналогична роли скрещивания в живой природе.
Задача формализуется таким образом, чтобы её решение могло быть закодировано в виде вектора («генотипа») генов. Где каждый ген может быть битом, числом или неким другим объектом. В классических реализациях ГА предполагается, что генотип имеет фиксированную длину. Однако существуют вариации ГА, свободные от этого ограничения.
Общая схема данного подхода:
1. Выбрать начальную случайную популяцию множества
решений и получить оценку качества для каждого решения (обычно она
пропорциональна ![]() ).
).
2. Создать и оценить следующую популяцию решений, используя эволюционные операторы: оператор выбора – с большой вероятностью предпочитает хорошие решения; оператор рекомбинации (обычно это «кроссовер») – создает новое решение на основе рекомбинации из существующих; оператор мутации – создает новое решение на основе случайного незначительного изменения одного из существующих решений.
3. Повторять шаг 2 до получения нужного результата.
Главным достоинством генетических алгоритмов в данном применении является то, что они ищут глобальное оптимальное решение. Большинство популярных алгоритмов оптимизации выбирают начальное решение, которое затем изменяется в ту или иную сторону. Таким образом получается хорошее разбиение, но не всегда самое оптимальное. Операторы рекомбинации и мутации позволяют получить решения, сильно не похожее на исходное – таким образом осуществляется глобальный поиск.
Рисунок 1.11 – Пример генетического алгоритма
1.4 Применение кластеризации
Кластерный анализ применяется в различных областях. Он полезен, когда нужно классифицировать большое количество информации, например, обзор многих опубликованных исследований, проводимых с помощью кластерного анализа.
Наибольшее применение кластеризация первоначально получила в таких науках как биология, антропология, психология. Для решения экономических задач кластеризация длительное время мало использовалась из-за специфики экономических данных и явлений. Так, в медицине используется кластеризация заболеваний, лечения заболеваний или их симптомов, а также таксономия пациентов, препаратов и т.д. В археологии устанавливаются таксономии каменных сооружений и древних объектов и т.д. В менеджменте примером задачи кластеризации будет разбиение персонала на различные группы, классификация потребителей и поставщиков, выявление схожих производственных ситуаций, при которых возникает брак. В социологии задача кластеризации - разбиение респондентов на однородные группы. В маркетинговых исследованиях кластерный анализ применяется достаточно широко - как в теоретических исследованиях, так и практикующими маркетологами, решающими проблемы группировки различных объектов. При этом решаются вопросы о группах клиентов, продуктов и т.д.
Так, одной из наиболее важных задач при применении кластерного анализа в маркетинговых исследованиях является анализ поведения потребителя, а именно: группировка потребителей в однородные классы для получения максимально полного представления о поведении клиента из каждой группы и о факторах, влияющих на его поведение. Важной задачей, которую может решить кластерный анализ, является позиционирование, т.е. определение ниши, в которой следует позиционировать новый продукт, предлагаемый на рынке. В результате применения кластерного анализа строится карта, по которой можно определить уровень конкуренции в различных сегментах рынка и соответствующие характеристики товара для возможности попадания в этот сегмент. С помощью анализа такой карты возможно определение новых, незанятых ниш на рынке, в которых можно предлагать существующие товары или разрабатывать новые.
Кластерный анализ также может быть удобен, например, для анализа клиентов компании. Для этого все клиенты группируются в кластеры, и для каждого кластера вырабатывается индивидуальная политика. Такой подход позволяет существенно сократить объекты анализа, и, в то же время, индивидуально подойти к каждой группе клиентов.
Таким образом, кластеризация, во-первых, применятся для анализа данных (упрощение работы с информацией, визуализация данных). Использование кластеризации упрощает работу с информацией, так как:
· достаточно работать с k представителями кластеров;
· легко найти «похожие» объекты – такой поиск применяется в ряде поисковых движков;
· происходит автоматическое построение каталогов;
· наглядное представление кластеров позволяет понять структуру множества объектов в пространстве.
Во-вторых, для группировки и распознавания объектов. Для распознавания образов характерно:
· построение кластеров на основе большого набора учебных данных;
· присвоение каждому из кластеров соответствующей метки;
· ассоциирование каждого объекта, полученного на вход алгоритма распознавания, с меткой соответствующего кластера.
Для группировки объектов характерно:
· сегментация изображений
· уменьшение количества информации

Рисунок 1.12 – Пример сегментации изображения
В-третьих, для извлечения и поиска информации, построения удобных классификаторов.
Извлечение и поиск информации можно рассмотреть на примере книг в библиотеке. Это наиболее известная система не автоматической классификации – LCC (Library of Congress Classification):
· метка Q означает книги по науке;
· подкласс QA – книги по математике;
· метки с QA76 до QA76.8 – книги по теоретической информатике.
Проблемами такой классификация является то, что иногда классификация отстает от быстрого развития некоторых областей науки, а также возможность отнести каждую книгу только к одной категории. Однако в этом случае приходит на помощь автоматическая кластеризация с нечетким разбиением на группы, что решает проблему одной категории, также новые кластера вырастают одновременно с развитием той или иной области науки.
2. СЕТЬ КОХОНЕНА
Сеть Кохонена - это одна из разновидностей нейронных сетей, которые используют неконтролируемое обучение. При таком обучении обучающее множество состоит лишь из значений входных переменных, в процессе обучения нет сравнивания выходов нейронов с эталонными значениями. Можно сказать, что такая сеть учится понимать структуру данных.
Идея сети Кохонена принадлежит финскому ученому Тойво Кохонену (1982 год). Основной принцип работы сетей - введение в правило обучения нейрона информации относительно его расположения.
В основе идеи сети Кохонена лежит аналогия со свойствами человеческого мозга. Кора головного мозга человека представляет собой плоский лист и свернута складками. Таким образом, можно сказать, что она обладает определенными топологическими свойствами (участки, ответственные за близкие части тела, примыкают друг к другу и все изображение человеческого тела отображается на эту двумерную поверхность). Во многих моделях ИНС решающую роль играют связи между нейронами, определяемые весовыми коэффициентами и указывающие место нейрона в сети. Однако в биологических системах, на пример, таких как мозг, соседние нейроны, получая аналогичные входные сигналы, реагируют на них сходным образом, т. е. группируются, образуя некоторые области. Поскольку при обработке многомерного входного образа осуществляется его проецирование на область меньшей размерности с сохранением его топологии, часто подобные сети называют картами (self-organizing feature map). В таких сетях существенным является учет взаимного расположения нейронов одного слоя.
Сеть Кохонена (самоорганизующаяся карта) относится к самоорганизующимся сетям, которые при поступлении входных сигналов, в отличие от сетей, использующих обучение с учителем, не получают информацию о желаемом выходном сигнале. В связи с этим невозможно сформировать критерий настройки, основанный на рассогласовании реальных и требуемых выходных сигналов ИНС, поэтому весовые параметры сети корректируют, исходя из других соображений. Все предъявляемые входные сигналы из заданного обучающего множества самоорганизующаяся сеть в процессе обучения разделяет на классы, строя так называемые топологические карты.
2.1 Структура сети Кохонена
Сеть Кохонена использует следующую модель (рисунок 2.1): сеть состоит из М нейронов, образующих прямоугольную решетку на плоскости — слой.
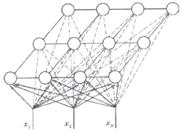
Рисунок 2.1 – Модель сети Кохонена
К нейронам, расположенным в одном слое, представляющем
собой двумерную плоскость, подходят нервные волокна, по которым поступает
N-мерный входной сигнал. Каждый нейрон характеризуется своим положением в слое
и весовым коэффициентом. Положение нейронов, в свою очередь, характеризуется
некоторой метрикой и определяется топологией слоя, при которой соседние нейроны
во время обучения влияют друг на друга сильнее, чем расположенные дальше.
Каждый нейрон образует взвешенную сумму входных сигналов с ![]() , если синапсы
ускоряющие, и
, если синапсы
ускоряющие, и ![]() - если тормозящие. Наличие связей
между нейронами приводит к тому, что при возбуждении одного из них можно
вычислить возбуждение остальных нейронов в слое, причем это возбуждение с
увеличением расстояния от возбужденного нейрона уменьшается. Поэтому центр
возникающей реакции слоя на полученное раздражение соответствует местоположению
возбужденного нейрона. Изменение входного обучающего сигнала приводит к
максимальному возбуждению другого нейрона и соответственно — к другой реакции
слоя. Сеть Кохонена может рассматриваться как дальнейшее развитие LVQ (Learning Vector Quantization). Отличие их состоит в
способах обучения.
- если тормозящие. Наличие связей
между нейронами приводит к тому, что при возбуждении одного из них можно
вычислить возбуждение остальных нейронов в слое, причем это возбуждение с
увеличением расстояния от возбужденного нейрона уменьшается. Поэтому центр
возникающей реакции слоя на полученное раздражение соответствует местоположению
возбужденного нейрона. Изменение входного обучающего сигнала приводит к
максимальному возбуждению другого нейрона и соответственно — к другой реакции
слоя. Сеть Кохонена может рассматриваться как дальнейшее развитие LVQ (Learning Vector Quantization). Отличие их состоит в
способах обучения.
2.2 Обучение сети Кохонена
Сеть Кохонена, в отличие от многослойной нейронной сети, очень проста; она представляет собой два слоя: входной и выходной. Элементы карты располагаются в некотором пространстве, как правило, двумерном.
Сеть Кохонена обучается методом последовательных приближений. В процессе обучения таких сетей на входы подаются данные, но сеть при этом подстраивается не под эталонное значение выхода, а под закономерности во входных данных. Начинается обучение с выбранного случайным образом выходного расположения центров.
В процессе последовательной подачи на вход сети обучающих примеров определяется наиболее схожий нейрон (тот, у которого скалярное произведение весов и поданного на вход вектора минимально). Этот нейрон объявляется победителем и является центром при подстройке весов у соседних нейронов. Такое правило обучения предполагает "соревновательное" обучение с учетом расстояния нейронов от "нейрона-победителя".
Обучение при этом заключается не в минимизации ошибки, а в подстройке весов (внутренних параметров нейронной сети) для наибольшего совпадения с входными данными.
Основной итерационный алгоритм Кохонена последовательно проходит ряд эпох, на каждой из которых обрабатывается один пример из обучающей выборки. Входные сигналы последовательно предъявляются сети, при этом желаемые выходные сигналы не определяются. После предъявления достаточного числа входных векторов синаптические веса сети становятся способны определить кластеры. Веса организуются так, что топологически близкие узлы чувствительны к похожим входным сигналам.
В результате работы алгоритма центр кластера устанавливается в определенной позиции, удовлетворительным образом кластеризующей примеры, для которых данный нейрон является "победителем". В результате обучения сети необходимо определить меру соседства нейронов, т.е. окрестность нейрона-победителя, которая представляет собой несколько нейронов, которые окружают нейрон-победитель.
Сначала к окрестности принадлежит большое число нейронов, далее ее размер постепенно уменьшается. Сеть формирует топологическую структуру, в которой похожие примеры образуют группы примеров, близко находящиеся на топологической карте.
Рассмотрим это более подробнее. Кохонен существенно упростил решение задачи, выделяя из всех нейронов слоя лишь один с-й нейрон, для которого взвешенная сумма входных сигналов максимальна:
![]() . (2.1)
. (2.1)
Отметим, что весьма полезной операцией предварительной об работки входных векторов является их нормализация:
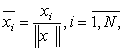 (2.2)
(2.2)
превращающая векторы входных сигналов в единичные с тем же направлением.
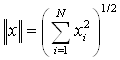 (2.3)
(2.3)
В этом случае вследствие того, что сумма весов каждого
нейрона одного слоя ![]() для всех нейронов этого слоя
одинакова и
для всех нейронов этого слоя
одинакова и ![]() ,
условие (2.1) эквивалентно условию:
,
условие (2.1) эквивалентно условию:
