

 Дипломная работа: Моделирование сети кластеризации данных в MATLAB NEURAL NETWORK TOOL
Дипломная работа: Моделирование сети кластеризации данных в MATLAB NEURAL NETWORK TOOL
Дипломная работа: Моделирование сети кластеризации данных в MATLAB NEURAL NETWORK TOOL
МОДЕЛИРОВАНИЕ СЕТИ КЛАСТЕРИЗАЦИИ ДАННЫХ В MATLAB NEURAL NETWORK TOOL
СОДЕРЖАНИЕ
Введение
1. Общие сведения о кластеризации
1.1 Понятие кластеризации
1.2 Процесс кластеризации
1.3 Алгоритмы кластеризации
1.3.1 Иерархические алгоритмы
1.3.2 k-Means алгоритм
1.3.3 Минимальное покрывающее дерево
1.3.4 Метод ближайшего соседа
1.3.5 Алгоритм нечеткой кластеризации
1.3.6 Применение нейронных сетей
1.3.7 Генетические алгоритмы
1.4 Применение кластеризации
2. Сеть Кохонена
2.1 Структура сети Кохонена
2.2 Обучение сети Кохонена
2.3 Выбор функции «соседства»
2.4 Карта Кохонена
2.5 Задачи, решаемые при помощи карт Кохонена
3. Моделирование сети кластеризации данных в MATLAB NEURAL NETWORK TOOLBOX
3.1 Самоорганизующиеся нейронные сети в MATLAB NNT
3.1.1 Архитектура сети
3.1.2 Создание сети
3.1.3 Правило обучения слоя Кохонена
3.1.4 Правило настройки смещений
3.1.5 Обучение сети
3.1.6 Моделирование кластеризации данных
3.2 Карта Кохонена в MATLAB NNT
3.2.1 Топология карты
3.2.2 Функции для расчета расстояний
3.2.3 Архитектура сети
3.2.4 Создание сети
3.2.5 Обучение сети
3.2.6 Моделирование одномерной карты Кохонена
3.2.7 Моделирование двумерной карты Кохонена
Выводы
Перечень ссылок
ВВЕДЕНИЕ
В настоящее время ни у кого не вызывает удивления проникновение компьютеров практически во все сферы человеческой деятельности. Совершенствование элементной базы, определяющей архитектуру компьютера, и распараллеливания вычислений позволяют быстро и эффективно решать задачи все возрастающей сложности. Решение многих проблем немыслимо без применения компьютеров. Однако, обладая огромным быстродействием, компьютер часто не в состоянии справиться с поставленной перед ним задачей так, как бы это сделал человек. Примерами таких задач могут быть задачи распознавания, понимания речи и текста, написанного от руки, и многие другие. Таким образом, сеть нейронов, образующая человеческий мозг, являясь, как и компьютерная сеть, системой параллельной обработки информации, во многих случаях оказывается более эффективной. Идея перехода от обработки заложенным в компьютер алгоритмом некоторых формализованных знаний к реализации в нем свойственных человеку приемов обработки информации привели к появлению искусственных нейронных сетей (ИНС).
Отличительной особенностью биологических систем является адаптация, благодаря которой такие системы в процессе обучения развиваются и приобретают новые свойства. Как и биологические нейронные сети, ИНС состоят из связанных между собой элементов, искусственных нейронов, функциональные возможности которых в той или иной степени соответствуют элементарным функциям биологического нейрона. Как и биологический прототип, ИНС обладает следующим свойствами:
· адаптивное обучение;
· самоорганизация;
· вычисления в реальном времени;
· устойчивость к сбоям.
Таким образом, можно выделить ряд преимуществ использования нейронных сетей:
· возможно построение удовлетворительной модели на нейронных сетях даже в условиях неполноты данных;
· искусственные нейронные сети легко работают в распределенных системах с большой параллелизацией в силу своей природы;
· поскольку искусственные нейронные сети подстраивают свои весовые коэффициенты, основываясь на исходных данных, это помогает сделать выбор значимых характеристик менее субъективным.
Сейчас мир переполнен различными данными и информацией - прогнозами погод, процентами продаж, финансовыми показателями и массой других. Часто возникают задачи анализа данных, которые с трудом можно представить в математической числовой форме. Например, когда нужно извлечь данные, принципы отбора которых заданы нечетко: выделить надежных партнеров, определить перспективный товар, проверить кредитоспособность клиентов или надежность банков и т.п. И для того, чтобы получить максимально точные результаты решения этих задач необходимо использовать различные методы анализа данных. В частности, можно использовать ИНС для кластеризации данных, что, на мой взгляд является наиболее перспективным подходом.
1. ОБЩИЕ СВЕДЕНИЯ О КЛАСТЕРИЗАЦИИ
1.1 Понятие кластеризации
Классификация – наиболее простая и распространенная задача. В результате решения задачи классификации обнаруживаются признаки, которые характеризуют группы объектов исследуемого набора данных - классы; по этим признакам новый объект можно отнести к тому или иному классу.
Кластеризация – это автоматическое разбиение элементов некоторого множества на группы в зависимости от их схожести. Синонимами термина "кластеризация" являются "автоматическая классификация", "обучение без учителя" и "таксономия".
Задача кластеризации сходна с задачей классификации, является ее логическим продолжением, но ее отличие в том, что классы изучаемого набора данных заранее не предопределены. Таким образом кластеризация предназначена для разбиения совокупности объектов на однородные группы (кластеры или классы). Если данные выборки представить как точки в признаковом пространстве, то задача кластеризации сводится к определению "сгущений точек".
Целью кластеризации является поиск существующих структур.
Кластеризация является описательной процедурой, она не делает никаких статистических выводов, но дает возможность провести разведочный анализ и изучить "структуру данных".
Само понятие "кластер" определено неоднозначно: в каждом исследовании свои "кластеры". Переводится понятие кластер как "скопление", "гроздь". В искусственных нейронных сетях под понятием кластер понимается подмножество «близких друг к другу» объектов из множества векторов характеристик. Следовательно, кластер можно охарактеризовать как группу объектов, имеющих общие свойства.
Характеристиками кластера можно назвать два признака:
· внутренняя однородность;
· внешняя изолированность.
В таблице 1.1 приведено сравнение некоторых параметров задач классификации и кластеризации.
Таблица 1.1
Сравнение классификации и кластеризации
| Классификация | Кластеризация | |
| Контролируемость обучения | Контролируемое обучение | Неконтролируемое обучение |
| Стратегия | Обучение с учителем | Обучение без учителя |
| Наличие метки класса | Обучающее множество сопровождается меткой, указывающей класс, к которому относится наблюдение | Метки класса обучающего множества неизвестны |
| Основание для классификации | Новые данные классифицируются на основании обучающего множества | Дано множество данных с целью установления существования классов или кластеров данных |
На рисунке 1.1 схематически представлены задачи классификации и кластеризации

Рисунок 1.1 – Сравнение задач классификации и кластеризации
Кластеры могут быть непересекающимися, или эксклюзивными, и пересекающимися. Схематическое изображение непересекающихся и пересекающихся кластеров дано на рисунке 1.2
Рисунок 1.2 – Непересекающиеся и пересекающиеся кластеры
1.2 Процесс кластеризации
Процесс кластеризации зависит от выбранного метода и почти всегда является итеративным. Он может стать увлекательным процессом и включать множество экспериментов по выбору разнообразных параметров, например, меры расстояния, типа стандартизации переменных, количества кластеров и т.д. Однако эксперименты не должны быть самоцелью - ведь конечной целью кластеризации является получение содержательных сведений о структуре исследуемых данных. Полученные результаты требуют дальнейшей интерпретации, исследования и изучения свойств и характеристик объектов для возможности точного описания сформированных кластеров.
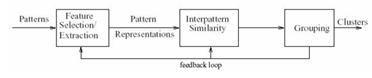
Рисунок 1.3 – Общая схема кластеризации
Кластеризация данных включает в себя следующие этапы:
а) Выделение характеристик.
Для начала необходимо выбрать свойства, которые характеризуют наши объекты, ими могут быть количественные характеристики (координаты, интервалы…), качественные характеристики (цвет, статус, воинское звание…) и т.д. Затем стоит попробовать уменьшить размерность пространства характеристических векторов, то есть выделить наиболее важные свойства объектов. Уменьшение размерности ускоряет процесс кластеризации и в ряде случаев позволяет визуально оценивать результаты. Выделенные характеристики стоит нормализовать. Далее все объекты представляются в виде характеристических векторов. Мы будем полностью отождествлять объект с его характеристическим вектором.
б) Определение метрики.
Следующим этапом кластеризации является выбор метрики, по которой мы будем определять близость объектов. Метрика выбирается в зависимости от:
· пространства, в котором расположены объекты;
· неявных характеристик кластеров.
Например, если все координаты объекта непрерывны и вещественны, а кластера должны представлять собой нечто вроде гиперсфер, то используется классическая евклидова метрика (на самом деле, чаще всего так и есть):
![]() . (1.1)
. (1.1)
в) Представление результатов.
Результаты кластеризации должны быть представлены в удобном для обработки виде, чтобы осуществить оценку качества кластеризации. Обычно используется один из следующих способов:
· представление кластеров центроидами;
· представление кластеров набором характерных точек;
· представление кластеров их ограничениями.
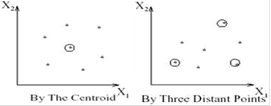
Рисунок 1.4 – Способы представления кластеров
Оценка качества кластеризации может быть проведена на основе следующих процедур:
· ручная проверка;
· установление контрольных точек и проверка на полученных кластерах;
· определение стабильности кластеризации путем добавления в модель новых переменных;
· создание и сравнение кластеров с использованием различных методов.
Разные методы кластеризации могут создавать разные кластеры, и это является нормальным явлением. Однако создание схожих кластеров различными методами указывает на правильность кластеризации.
1.3 Алгоритмы кластеризации
Следует отметить, что в результате применения различных методов кластерного анализа могут быть получены кластеры различной формы. Например, возможны кластеры "цепочного" типа, когда кластеры представлены длинными "цепочками", кластеры удлиненной формы и т.д., а некоторые методы могут создавать кластеры произвольной формы. Различные методы могут стремиться создавать кластеры определенных размеров (например, малых или крупных), либо предполагать в наборе данных наличие кластеров различного размера. Некоторые методы кластерного анализа особенно чувствительны к шумам или выбросам, другие - менее. В результате применения различных методов кластеризации могут быть получены неодинаковые результаты, это нормально и является особенностью работы того или иного алгоритма. Данные особенности следует учитывать при выборе метода кластеризации. На сегодняшний день разработано более сотни различных алгоритмов кластеризации.
Классифицировать алгоритмы можно следующим образом:
· строящие «снизу вверх» и «сверху вниз»;
· монотетические и политетические;
· непересекающиеся и нечеткие;
· детерминированные и стохастические;
· потоковые (оnline) и не потоковые;
· зависящие и не зависящие от порядка рассмотрения объектов.
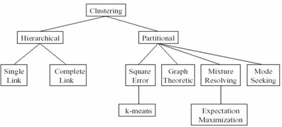
Рисунок 1.5 – Классификация алгоритмов кластеризации
Далее будут рассмотрены основные алгоритмы кластеризации.
1.3.1 Иерархические алгоритмы
Результатом работы иерархических алгоритмов является дендограмма (иерархия), позволяющая разбить исходное множество объектов на любое число кластеров. Два наиболее популярных алгоритма, оба строят разбиение «снизу вверх»:
· single-link – на каждом шаге объединяет два кластера с наименьшим расстоянием между двумя любыми представителями;
· complete-link – на каждом шаге объединяет два кластера с наименьшим расстоянием между двумя наиболее удаленными представителями.
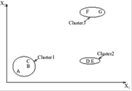
Рисунок 1.6 – Пример single-link алгоритма
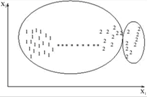
Рисунок 1.7 – Пример complete-link алгоритма
1.3.2 k-Means алгоритм
Данный алгоритм состоит из следующих шагов:
1. Случайно выбрать k точек, являющихся начальными координатами «центрами масс» кластеров (любые k из n объектов, или вообще k случайных точек).
2. Отнести каждый объект к кластеру с ближайшим «центром масс».
3. Пересчитать «центры масс» кластеров согласно текущему членству.
4. Если критерий остановки не удовлетворен, вернуться к шагу 2.
В качестве критерия остановки обычно выбирают один из двух: отсутствие перехода объектов из кластера в кластер на шаге 2 или минимальное изменение среднеквадратической ошибки.
Алгоритм чувствителен к начальному выбору «центр масс».
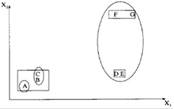
Рисунок 1.8 – Пример k-Means алгоритма
1.3.3 Минимальное покрывающее дерево
Данный метод производит иерархическую кластеризацию «сверху вниз». Сначала все объекты помещаются в один кластер, затем на каждом шаге один из кластеров разбивается на два, так чтобы расстояние между ними было максимальным.
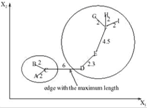
Рисунок 1.9 – Пример алгоритма минимального покрывающего дерева
