

 Реферат: Теория вероятностей
Реферат: Теория вероятностей
Вопрос 25
Функцией (или интегралом вероятностей) Лапласа называется функция
![]()
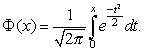 При решении
задач, как правило, требуется найти значение функции по известному значению аргумента
или, наоборот, по известному значению функции требуется найти значение
аргумента. Для этого пользуются таблицей значений функции Лапласа и учитывают
следующие свойства функции
При решении
задач, как правило, требуется найти значение функции по известному значению аргумента
или, наоборот, по известному значению функции требуется найти значение
аргумента. Для этого пользуются таблицей значений функции Лапласа и учитывают
следующие свойства функции ![]()
![]() 10. Функция Лапласа нечётная, т.е.
10. Функция Лапласа нечётная, т.е.
20. Функция Лапласа монотонно возрастающая, причём (
практически можно считать, что уже при ![]() . Так при
. Так при ![]() ).
).

Вопрос 26
Неравенство Чебышева: Если известна дисперсия С.В., то с ее помощью можно оценить вероятность отклонения этой величины на заданное значение от своего мат. ожидания, причем оценка вероятности отклонения зависит лишь от дисперсии. Соответствующую оценку вероятности дает неравенство Чебышева. Неравенство Чебышева является частным случаем более общего неравенства, позволяющего оценить вероятность события, состоящего в том, что С.В. Х превзойдет по модулю произвольное число t>0. PX<=1/t*2 M(X – MX)*2=1/t*2 DX – неравенство Чебышева. Оно справедливо для любых С.В., имеющих дисперсию; оценка вероятности в нем не зависит от закона распределения С.В. Х.
Под законом больших числе понимается обобщенное название группы теорем, утверждающих, что при неограниченном увеличении числа испытаний средние величины стремятся к некоторым постоянным.
Теорема Чебышева: Если последовательность попарно независимых С.В. Х1,Х2,Х3,…,Xn,… имеет конечные мат. ожидания и дисперсии этих величин равномерно ограничены (не превышают постоянного числа С), то среднее арифметическое С.В. сходится по вероятности к среднему арифметическому их мат. ожиданий, т.е. если эпселен – любое положительное число, то: lim при n стремящемся к бесконечности P(|1/n сумма по i от 1 до n Xi – 1/n сумма по i от 1 до n M(Xi)|<эпселен)=1. В частности, среднее арифметическое последовательности попарно независимых величин, дисперсии которых равномерно ограничены и которые имеют одно и тоже мат. ожидание а, сходится по вероятности к мат. ожиданию а, т.е. если эпселен – любое положительное число, то: lim при n стремящемся к бесконечности P(|1/n сумма по i от 1 до n Xi – a|<эпселен)=1.
Теорема Бернулли: Если вероятность успеха в каждом из п независимых испытаний постоянна и равна р, то для произвольного, сколь угодно малого ε > 0 справедливо предельное равенство
![]()
где т — число успехов в серии из п испытаний.
Вопрос 27
Локальная теорема Лапласа. Вероятность того, что в n независимых испытаниях, в каждом из которых вероятность появления события равна р(0<p<1), событие наступит ровно k раз (безразлично, в какой последовательности), приближенно равна (тем точнее, чем больше n). Pn(k)=1/(корень из npq)*фи(х). Здесь Фи(х)=1/(корень из 2пи)*е в степени –х*2/2, x=k – np/(корень из npq). Интегральная теорема Лапласа. Вероятность того, что в n независимых испытаниях, в каждом из которых вероятность появления события равна р(0<p<1), событие наступит не меньше k1 раз и не более k2 раз, приближенно равна: P(k1;k2)=Ф(х’’) – Ф(х’). Здесь Ф(х)=1/(корень из 2пи) * интеграл от0 до х е в степени –(z*2/2)dz – функция Лапласа, х’=(k1 – np)/(корень из npq), х’’=(k2 – np)/(корень из npq).
Вопрос 28
Двумерной называют С.В. (Х,Y), возможные значения которой есть пары чисел (x,y). Составляющие Х и Y, рассматриваемые одновременно, образуют систему двух С.В. Дискретной называют двумерную величину, составляющие которой дискретны. Непрерывной называют двумерную величину, составляющие которой непрерывны. Законом распределения Д.С.В. называют соответствие между возможными значениями и их вероятностями. Функция распределения вероятностей Д.С.В. называют функцию F(X,Y), определяющую для каждой пары чисел (х,y) вероятность того, что Х примет значение, меньшее х, при этом Y примет значение, меньшее y: F(x,y)=P(X<x,Y<y). Свойства:1) Значения функции распределения удовлетворяют двойному неравенству: 0<=F(x,y)<=1. 2) Функция распределения есть неубывающая функция по каждому аргументу:F(x2,y)>=F(x1,y), если х2>x1. F(x,y2)>=F(x,y1), если y2>y1. 3) Имеют место предельные соотношения: 1) F(-бесконечность, у)=0, 2) F(x,-бесконечность)=0, 3) F(-бесконечность, -бесконечность)=0, 4) F(бесконечность, бесконечность)=1. 4) а) при у=бесконечность функция распределения системы становится функцией распределения составляющей Х: F(x,бесконечность)=F1(x). Б) при х=бесконечность функция распределения системы становится функцией распределения составляющей У: F(бесконечность, у)=F2(y).
Вопрос 29
Вопрос 30
Корреляционным моментом СВ x и h называется мат. ожидание произведения отклонений этих СВ. mxh=М((x—М(x))*(h—М(h)))
Для вычисления корреляционного момента может быть использована формула:
mxh=М(x*h)—М(x)*М(h) Доказательство: По определению mxh=М((x—М(x))*(h—М(h))) По свойству мат. ожидания
mxh=М(xh—М(h)—hМ(x)+М(x)*М(h))=М(xh)—М(h)*М(x)—М(x)*М(h)+М(x)*М(h)=М(xh)—М(x)*(h)
Предполагая, что x и h независимые СВ, тогда mxh=М(xh)—М(x)*М(h)=М(x)*М(h)—М(x)*М(h)=0; mxh=0. Можно доказать, что если корреляционный момент=0, то СВ могут быть как зависимыми, так и независимыми. Если mxh не равен 0, то СВ x и h зависимы. Если СВ x и h зависимы, то корреляционный момент может быть равным 0 и не равным 0. Можно показать, что корреляционный момент характеризует степень линейной зависимости между составляющими x и h. При этом корреляционный момент зависит от размерности самих СВ. Чтобы сделать характеристику линейной связи x и h независимой от размерностей СВ x и h, вводится коэффициент корреляции:
Кxh=mxh/s(x)*s(h) Коэффициент корреляции не зависит от разностей СВ x и h и только показывает степень линейной зависимости между x и h, обусловленную только вероятностными свойствами x и h. Коэффициент корреляции определяет наклон прямой на графике в системе координат (x,h) Свойства коэффициента корреляции.
1. -1<=Кxh<=1
Если Кxh =±1, то линейная зависимость между x и h и они не СВ.
2. Кxh>0, то с ростом одной составляющей, вторая также в среднем растет.
Кxh<0, то с убыванием одной составляющей, вторая в среднем убывает.
3. D(x±h)=D(x)+D(h)±2mxh
Доказательство.
D(x±h)=M((x±h)2)—M2(x±h)=M(x2±2xh+h2)—(M(x)±M(h))2=M(x2)±2M(xh)+M(h2)—+M2(x)+2M(x)*M(h)—M2(h)=D(x)+D(h)±2(M(xh))—M(x)*M(h)=D(x)+D(h)±2mxh
Вопрос 31
Мат. статистика опирается на теорию вероятностей, и ее цель – оценить характеристики генеральной совокупности по выборочным данным. Генеральной совокупностью называется вероятностное пространство {омега,S,P} (т.е. пространство элементарных событий омега с заданным на нем полем событий S и вероятностями Р) и определенная на этом пространстве С.В. Х. Случайной выборкой или просто выборкой объема n называется последовательность Х1,Х2,…,Xn, n независимых одинаково распределенных С.В., распределение каждой из которых совпадает с распределением исследуемой С.В. Х. Иными словами, случайная выборка – это результат n последовательных и независимых наблюдений над С.В. Х, представляющей генеральную совокупность.
Вопрос 32
Расположив элементы выборки в порядке неубывания, получим вариационный ряд х1 х2, ...-, хп. Если в вариационном ряду есть повторяющиеся элементы, то выборку можно записать в виде статистического ряда распределения, т.е. в виде таблицы
![]()
в которой хi'; (i= 1, 2,..., к) — это варианты
(расположенные по возрастанию различные
элементы выборки), а![]()
отвечающие этим значениям частости (здесь mi — частота варианты х'i, т.е. количество ее появлений в выборке). При этом, очевидно,
![]() Кривая распределения частости - это ломаная с вершинами (х’i; Pi).
Кривая распределения частости - это ломаная с вершинами (х’i; Pi).
Выборочное среднее (4.1.1) и выборочную дисперсию (4.1.8) при этом можно вычислить по формулам
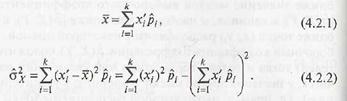
Для непрерывных случайных величин при достаточно больших объемах выборки п вместо статистического ряда распределения используют интервальный вариационный ряд
![]()
где v - число интервалов одинаковой ширины h = (xn-x1)/(1+3,322lgn) (х1 и хп - соответственно минимальный и максимальный элементы выборки; значение h рассчитывается с числом знаков после запятой, на единицу большим, чем в исходныхданных). Границы интервалов [aj, aj+i) рассчитываются по правилу: a1=x1-h/2, а2 = а1 + h, а3 = а2 + h, ...;
формирование интервалов заканчивается, как только для конца av+1 очередного интервала выполняется условие av+1 > хп. Выборочная ча-
стость ![]() где mi — число вариант, попавших в i-й интервал
где mi — число вариант, попавших в i-й интервал
(i= 1,2, ...,v). Выборочным аналогом плотности распределения fx(x) случайной величины X служит выборочная плотность распределения
Вопрос 33
Выборочным аналогом плотности распределения fx(x) случайной величины X служит выборочная плотность распределения
![]() при х Î[ai; ai+1) (i=
1, 2,..., V), ее график
называется гис
при х Î[ai; ai+1) (i=
1, 2,..., V), ее график
называется гис
тограммой, а ломаная с вершинами в точках![]() где через
где через
х’=(ai+ai+1)/2 обозначены середины интервалов, — полигоном частот.
Выборочное среднее и выборочную дисперсию при этом вычисляют по формулам (4.2.1), (4.2.2)
соответственно, в которых к = v.
По выборочной плотности распределения легко построить выборочную функцию распределения, при
этом линия, соединяющая точки![]() называется кумулятой
называется кумулятой
Гистограмма (тонкая линия), полигон частот (полужирная линия) (а) и кумулята (б)
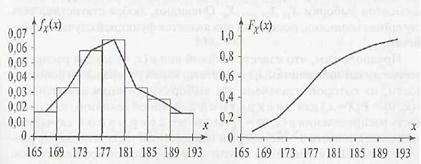
Вопрос 34
Вопрос 35
Прежде всего, от оценки θn хотелось бы требовать, чтобы по мере роста числа наблюдений п она стремилась к оцениваемому параметру, т.е. чтобы для любого сколь угодно малого £>0 было справедливо предельное равенство
![]()
Также от «хорошей» оценки естественно требовать, чтобы она не содержала систематической ошибки, т.е. при любом фиксированном объеме выборки результат осреднения по всем возможным выборкам данного объема должен приводить к точному значению параметра:
![]()
Наконец, от оценки θn желательно требовать, чтобы она была наиболее точной в некотором классе оценок в, т.е. имела минимальную дисперсию:
![]()
Вопрос 36
Статистической оценкой K * неизвестного параметра K теоретического распределения называют функцию f(X1,X2,…,Xn) от наблюдаемых С.В. X1,X2,…,Xn. Точечной называют статистическую оценку, которая определяется одним числом K *=f(x1,x2,…,xn), где х1,х2,…,xn – результаты n наблюдений над количественным признаком Х (выборка). Несмещенной называют точечную оценку, мат. ожидание которой равно оцениваемому параметру при любом объеме выборки. Смещенной называют точечную оценку, мат. ожидание которой не равно оцениваемому параметру. Несмещенной оценкой генеральной средней (мат. ожидания) служит выборочная средняя: Хв=(сумма по i от 1 до k nixi)/n, где xi – варианта выборки, ni – частота варианты xi, n=сумма по i от 1 до k ni – объем выборки.
Вопрос 37
Вопрос38
Метод моментов точечной оценки неизвестных параметров заданного распределения состоит в приравнивании теоретических моментов соответствующим эмпирическим моментам того же порядка. Если распределение определяется одним параметром, то для его отыскания приравнивают один теоретический момент одному эмпирическому моменту того же порядка. Например, можно приравнять начальный теоретический момент первого порядка начальному эмпирическому моменту первого порядка: v1=M1. Учитывая, что v1=M(X) и М1=Хв, получим М(Х)=Хв. Если распределение определяется двумя параметрами, то приравнивают два теоретических момента двум соответствующим эмпирическим моментам того же порядка. Учитывая, что v1=M(X),M1=Хв,мю=D(X),m2=Dв, имеем систему: М(Х)=Хв, D(X)=Dв.
