

 Реферат: Операционные системы
Реферат: Операционные системы
1. open - Открытие имеющегося файла. Одним из параметров этой функции является строка с именем файла, а возвращает она некоторое число, которое называется дескриптором файла. В теле процесса пользователя, а также в данных, ассоциированных с этим процессом, размещается (кроме кода и данных, разумеется) некоторая служебная информация, в частности, таблица файловых дескрипторов. Она, как и все таблицы в системе UNIX, позиционная, т.е. номер дескриптора соответствует номеру записи в этой таблице. С файловым дескриптором (ФД) ассоциировано имя файла и все необходимые атрибуты для работы с ним. Номера ФД уникальны в пределах одного процесса. Есть аналогичная функция create - функция открытия нового файла.
2. read/write - системные вызовы чтения/записи, параметрами которых является номер ФД и некоторые атрибуты, которые не так важны для нашего рассмотрения.
3. close - системный вызов завершения работы с файлом, параметром которого является номер ФД. После обращения к этой функции ФД становится свободным, а работа данного процесса с файлом завершается.
Вот некоторые системные вызовы, обеспечивающие ввод/вывод (кстати, они почти не добавляют кода к вашей программе). Подробности посмотрите самостоятельно. Я обратил ваше внимание, что это системные вызовы, потому что ввод/вывод можно осуществлять и через библиотеки ввода/вывода. Для этого существует, так называемый, файловый обмен и функции fopen, fread, и т.д. (с префиксом f). Это библиотечные функции. Эти функции сами обращаются к низкоуровневым функциям внутри себя.
Рассмотрим организацию обмена с системной точки зрения в операционной системе UNIX. При организации обмена операционная система подразделяет данные на две категории: данные, ассоциированные с процессом пользователя, и данные, ассоциированные с операционной системой.
Таблица индексных дескрипторов открытых файлов. Первая таблица данных, ассоциированных с операционной системой, - таблица индексных дескрипторов открытых файлов (ТИДОФ). Эта таблица содержит записи, каждая из которых содержит копию индексного дескриптора для каждого открытого в системе файла. Через эту копию осуществляется доступ к блокам файлов. Каждая записей таблицы содержит также поле, характеризующее количество открытых в системе файлов, использующих данный дескриптор (счетчик). То есть, если один и тот же файл открыт от имени двух процессов, то запись в ТИДОФ создается одна, но каждое дополнительное открытие этого файла увеличивает счетчик на единицу.
Таблица файлов. Таблица файлов (ТФ) содержит информацию об имени открытого файла, и имеет ссылку на ТИДОФ.
Лекция №9
Мы говорили, что система может работать с содержимым файла в том и только том случае, если процесс зарегистрировал свое желание работать с этим файлом. Факт такой регистрации называется открытием файла. При открытии файла в пределах процесса каждому имени открываемого файла (открываться может уже существующий файл, либо новый) ставится в соответствие уникальное целое число, которое называется файловым дескриптором (ФД). В пределах процесса ФД имеют нумерацию от 0 до k-1. Значение k - это параметр настройки операционной системы, определяющий, какое количество одновременно открытых файлов может быть у процесса. Здесь следует отметить, что мы говорим о количестве одновременно открытых файлов (так же написано в любой книжке по UNIX-у), однако, на самом деле, k - это максимальное количество ФД, которые могут быть ассоциированы с одним файлом, потому что один и тот же файл в пределах процесса можно открыть два раза, и образуется два ФД. К чему это приведет, мы рассмотрим несколько позже, но это вполне корректно. После открытия файла, все операции обмена осуществляются через указания файлового дескриптора (т.е. имя более нигде не указывается). С каждым файловым дескриптором ассоциирован ряд параметров (о них чуть позже).
Давайте посмотрим, как организуется ввод/вывод, а точнее обработка низкоуровнего обмена, с точки зрения операционной системы. Сейчас будет рассказано о логической схеме организации ввода/вывода, ибо реальная схема устроена несколько иначе, но это для нас не так важно.
Все данные, с которыми оперирует система, подразделяются на два класса. Первый тип данных - данные, ассоциированные с операционной системой, то есть общесистемные данные. К этим данным относится ТИДОФ. Размер таблицы фиксирован и определяется количеством одновременно открытых ФД. Каждая запись в этой таблице содержит некоторую информацию, среди которой нас будет интересовать следующая:
1) Копия ИД открытого файла. Для любого открытого файла, ИД, который характеризует содержимое этого файла, копируется и размещается в ТИДОФ. После этого все манипуляции с файлом (например, изменение адресации файла) происходят с копией ИД, а не с самим ИД на диске. ТИДОФ размещается в оперативной памяти, т.е. доступ к информации в ней осуществляется быстро.
2) Счетчик открытых в данный момент файлов, связанных с данным ИД. Это означает, что для любого количества открытий файла, связанного с данным ИД, система работает с единственной копией этого ИД.
Теперь перейдем к, так называемой, таблице файлов (ТФ). Таблица файлов состоит из фиксированного количества записей. Каждая запись ТФ соответствует открытому в системе файлу {{или точнее ФД}}. При этом в подавляющем большинстве случаев это есть взаимно однозначное соответствие. Тот случай, когда это не есть взаимно однозначное соответствие, мы рассмотрим ниже. Каждая запись ТФ содержит указатели чтения/записи по файлу. Это означает, что, если открыт один и тот же файл в двух процессах или дважды в одном процессе, то с каждым открытием связан свой указатель, и они друг от друга не зависят (почти всегда, за исключением некоторых случаев). Каждая запись ТФ содержит, так называемый, индекс наследственности - это есть некоторое целое число.
Это данные уровня операционной системы, т.е. данные, которые описывают состояние проблемы в системе в целом.
С каждым процессом связана, так называемая, таблица открытых файлов (ТОФ). Номер записи в данной таблице есть номер ФД. Каждая строка этой таблицы имеет ссылку на соответствующую строку ТФ. Это означает, что информация об указателях, связанных с ФД, как бы разорвана. С одной стороны, файловые дескрипторы - это данные, являющиеся атрибутом процесса, с другой стороны, указатель - это данные, являющиеся атрибутом операционной системы. Казалось бы, не логично, и сейчас мы рассмотрим, в чем эта нелогичность проявляется. Для этого кратко рассмотрим концептуальные вопросы, связанные с формированием процесса. Операционная система UNIX имеет функцию fork(). Это системный вызов. При обращении к этому системному вызову в системе происходит некоторое действие, которое для большинства из вас может показаться бессмысленным, - происходит копирование процесса, в котором встретилась эта функция, т.е. создается процесс-двойник. Для чего это нужно, я скажу несколько позже.
Формирование процесса-двойника обладает следующими свойствами. Первое свойство: процесс-сын, который будет сформирован после обращения к функции fork(), имеет все те файлы, которые были открыты в процессе-отце. Второе - система позволяет некоторыми своими средствами, идентифицировать, где процесс-отец, а где процесс-сын, хотя в общем случае они абсолютно одинаковы.
Предположим, есть процесс №1, и с ним ассоциирована таблица открытых файлов №1. В этом процессе открыт файл с именем Name, и этому файлу поставлен в соответствие файловый дескриптор I. Это означает, что в соответствующей строке ТОФ будет запись, имеющая ссылку на ТФ. В ТФ определены какие-то атрибуты, связанные с открытием файла, а также имеется указатель чтения/записи, т.е. тот указатель, по которому мы работаем, обмениваясь информацией с файлом. Записи в ТФ имеют ссылку на ТИДОФ, в которой находится копия ИД, соответствующего файлу с именем Name.
Предположим, что в этом процессе еще раз открыт файл с именем Name. Система поставила ему в соответствие файловый дескриптор J. Т.е. этому открытию соответствует J-тая строка ТОФ первого процесса. В этой записи будет ссылка на запись ТФ, которая поставлена в соответствие второму открытию файла Name. И пока индексы наследственности для обоих случаев будут равны единице. В этой записи будут свои, связанные с этим открытием, указатели чтения/записи. Указатели файловых дескрипторов I и J независимы друг от друга, т.е. при чтении/записи через файловый дескриптор I, указатель файлового дескриптора J не изменится. Эта запись будет ссылаться на тот же самый индексный дескриптор из ТИДОФ, и значение счетчика будет равно двум.
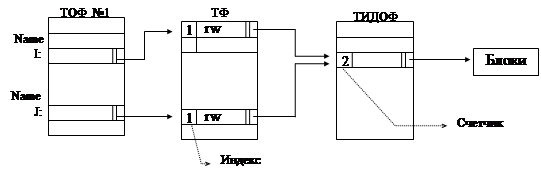
![]()
![]()
![]()
![]() Предположим,
процесс №1 выполнил обращение к функции fork(),
образовалась копия процесса, причем, обе копии начинают работать на выходе из fork(), и со вторым процессом будет ассоциирована ТОФ №2. Так же будет открыт
файл Name по ИД I
и по
ИД J. Но в этом
случае, когда процесс получил открытые файлы в наследство от родителя, то
ссылки из соответствующих строк ТОФ будут происходить не на новые записи ТФ, а
на те же самые, к которым ссылались соответствующие ФД у родителя. У этих процессов
указатели чтения записи будут одинаковы, т.е. если передвинуть указатель в
одном процессе, то он автоматически передвинется и для другого процесса. Этот
случай, как раз тот, когда нет взаимно однозначного соответствия между строками
ТФ и строками ТОФ. При порождении этих ссылок счетчик увеличивается на два. И,
соответственно, из ИД, за счет адресации блоков, осуществляется доступ к блокам
файлов. Такая информационная организация обмена означает, что обмен с
содержимым каждого файла осуществляется централизованно, т.е. в конечном итоге,
все заказы на обмен идут через одну единственную запись, сколько бы файлов,
связанных с этим ИД, не было открыто в системе. Здесь нет никаких коллизий,
когда во времени начинается путаница в выполненных, или невыполненных обменах,
связанных с одним дескриптором.
Предположим,
процесс №1 выполнил обращение к функции fork(),
образовалась копия процесса, причем, обе копии начинают работать на выходе из fork(), и со вторым процессом будет ассоциирована ТОФ №2. Так же будет открыт
файл Name по ИД I
и по
ИД J. Но в этом
случае, когда процесс получил открытые файлы в наследство от родителя, то
ссылки из соответствующих строк ТОФ будут происходить не на новые записи ТФ, а
на те же самые, к которым ссылались соответствующие ФД у родителя. У этих процессов
указатели чтения записи будут одинаковы, т.е. если передвинуть указатель в
одном процессе, то он автоматически передвинется и для другого процесса. Этот
случай, как раз тот, когда нет взаимно однозначного соответствия между строками
ТФ и строками ТОФ. При порождении этих ссылок счетчик увеличивается на два. И,
соответственно, из ИД, за счет адресации блоков, осуществляется доступ к блокам
файлов. Такая информационная организация обмена означает, что обмен с
содержимым каждого файла осуществляется централизованно, т.е. в конечном итоге,
все заказы на обмен идут через одну единственную запись, сколько бы файлов,
связанных с этим ИД, не было открыто в системе. Здесь нет никаких коллизий,
когда во времени начинается путаница в выполненных, или невыполненных обменах,
связанных с одним дескриптором.

При любом формировании нового процесса, система априори устанавливает нулевой, первый и второй файловые дескрипторы из ТОФ, связывая их с предопределенными файлами. Нулевой ФД связан с системным файлом ввода, с ним обычно ассоциировано внешнее устройство клавиатура. Первый ФД - это стандартный файл вывода, обычно с ним ассоциирован экран монитора. Второй ФД - это стандартный файл вывода диагностических сообщений, с ним также обычно ассоциирован экран монитора.
Рассмотрим для примера типовые действия при обращении к тем или иным системным вызовам.
Обращение к функции fork(). Как известно, при обращении к этой функции система создает копию исходного процесса. При этом система дублирует ТОФ одного процесса в ТОФ процесса-наследника, а также увеличивает на единицу индекс наследственности в строках ТФ, ассоциированных с открытыми файлами исходного процесс, а также увеличивает счетчик открытых файлов, связанных с данным ИД, в ТИДОФ.
Обращение к функции open(). При обращении к этой функции происходит следующее:
1. По полному имени определяется каталог, в котором размещен файл.
2. Определяется номер ИД. По номеру ИД осуществляется поиск в таблице ТИДОФ.
3. Если запись с заданным номером обнаружена, фиксируем номер соответствующей строки ТИДОФ и переходим к шагу 5.
4. В случае если строка не обнаружена, происходит формирование новой строки, соответствующей новому ИД и фиксируется ее номер.
5. Корректируем счетчик ссылок (стрелок) на запись ТИДОФ. Номер записи в ТИДОФ записывается в запись ТФ, а также в ТОФ устанавливается ссылка на соответствующую запись ТФ. После этого в программу возвращается номер сроки ТОФ, в которой находится ссылка на запись в ТФ.
При операциях ввода/вывода действия системы очевидны.
Взаимодействие с устройствами. Мы уже говорили, что все устройства, которые обслуживаются операционной системой UNIX, могут быть классифицированы на два типа - байт-ориентированные устройства и блок-ориентированные устройства. Следует отметить, что одно и то же устройство в системе может рассматриваться и как байт-ориентированное, и как блок-ориентированное (пример - оперативная память). Соответственно, есть драйверы блок-ориентированные и байт-ориентированные. На прошлой лекции мы рассматривали специальные файлы, ассоциированные с внешними устройствами, и говорили о том, что есть таблица драйверов блок-ориентированных устройств и таблица драйверов байт-ориентированных устройств. Соответственно, на эти таблицы имеются ссылки в ИД специальных файлов.
Основной особенностью организации работы с блок-ориентированными устройствами является возможность буферизации обмена. Суть заключается в следующем. В оперативной памяти системы организован пул буферов, где каждый буфер имеет размер в один блок. Каждый из этих блоков может быть ассоциирован с драйвером одного из физических блок-ориентированных устройств.
Рассмотрим, как выполняется последовательность действий при исполнении заказа на чтение блока. Будем считать, что поступил заказ на чтение N-ого блока из устройства с номером M.
1. Среди буферов буферного пула осуществляется поиск заданного блока, т.е. если обнаружен буфер, содержащий N-ый блок М-ого устройства, то фиксируем номер этого буфера. В этом случае, обращение к реальному физическому устройству не происходит, а операция чтения информации является представлением информации из найденного буфера. Переходим на шаг 4.
2. Если поиск заданного буфера неудачен, то в буферном пуле осуществляется поиск буфера для чтения и размещения данного блока. Если есть свободный буфер (реально, эта ситуация возможна только при старте системы), то фиксируем его номер и переходим к шагу 3. Если свободного буфера не нашли, то мы выбираем буфер, к которому не было обращений самое долгое время. В случае если в буфере имеется установленный признак произведенной записи информации в буфер, то происходит реальная запись размещенного в буфере блока на физической устройство. Затем фиксируем его номер и также переходим к пункту 3.
3. Осуществляется чтение N-ого блока устройства М в найденный буфер.
4. Происходит обнуление счетчика времени в данном буфере и увеличение на единицу счетчиков в других буферах.
5. Передаем в качестве результата чтения содержимое данного буфера.
Вы видите, что здесь есть оптимизация, связанная с минимизацией реальных обращений к физическому устройству. Это достаточно полезно при работе системы. Запись блоков осуществляется по аналогичной схеме. Таким образом организована буферизация при низкоуровневом вводе/выводе. Преимущества очевидны. Недостатком является то, что система в этом случае является критичной к несанкционированным выключениям питания, т.е. ситуация, когда буфера системы не выгружены, а происходит нештатное прекращение выполнения программ операционной системы, что может привести к потере информации.
Второй недостаток заключается в том, что за счет буферизации разорваны во времени факт обращения к системе за обменом и реальный обмен. Этот недостаток проявляется в случае, если при реальном физическом обмене происходит сбой. Т.е. необходимо, предположим, записать блок, он записывается в буфер, и получен ответ от системы, что обмен закончился успешно, но когда система реально запишет этот блок на ВЗУ, неизвестно. При этом может возникнуть нештатная ситуация, связанная с тем, что запись может не пройти, предположим, из-за дефектов носителя. Получается ситуация, при которой обращение к системе за функцией обмена для процесса прошло успешно (процесс получил ответ, что все записано), а, на самом деле, обмен не прошел.
Таким образом, эта система рассчитана на надежную аппаратуру и на корректные профессиональные условия эксплуатации. Для борьбы с вероятностью потери информации при появлении нештатных ситуаций, система достаточно «умна», и действует верно. А именно, в системе имеется некоторый параметр, который может оперативно меняться, который определяет периоды времени, через которые осуществляется сброс системных данных. Второе - имеется команда, которая может быть доступна пользователю, - команда SYNC. По этой команде осуществляется сброс данных на диск. И третье - система обладает некоторой избыточностью, позволяющей в случае потери информации, произвести набор действий, которые информацию восстановят или спорные блоки, которые не удалось идентифицировать по принадлежности к файлу, будут записаны в определенное место файловой системы. В этом месте их можно попытаться проанализировать и восстановить вручную, либо что-то потерять. Наш университет одним из первых в стране начал эксплуатировать операционную систему UNIX, и сейчас уже можно сказать, что проблем ненадежности системы, с точки зрения фатальной потери информации, не было.
