

 Шпаргалка: Лекции по количественной оценке информации
Шпаргалка: Лекции по количественной оценке информации
Для того чтобы определить кодовое расстояние между двумя комбинациями двоичного кода, достаточно просуммировать эти комбинации по модулю 2 и подсчитать число единиц в полученной комбинации.
Понятие кодового расстояния хорошо усваивается на примере построения геометрических моделей кодов. На геометрических моделях в вершинах n-угольников, где n-значность кода, расположены кодовые комбинации, а количество ребер n-угольника, отделяющих одну комбинацию от другой, равно кодовому расстоянию.
Если кодовая комбинация двоичного кода А отстоит
от кодовой комбинации В на расстоянии d, то это значит, что в коде А
нужно d символов заменить на обратные, чтобы получить код В, но это не
означает, что нужно d добавочных символов, чтобы код обладал данными корректирующими свойствами. В двоичных кодах для
обнаружения одиночной ошибки достаточно иметь 1 дополнительный символ
независимо от числа информационных разрядов кода, а минимальное кодовое
расстояние ![]()
Для обнаружения и исправления
одиночной ошибки соотношение между числом информационных разрядов ![]() и числом корректирующих
разрядов
и числом корректирующих
разрядов ![]() должно удовлетворять
следующим условиям:
должно удовлетворять
следующим условиям:
![]() (59)
(59)
![]() 60)
60)
при этом подразумевается, что общая длина кодовой комбинации
![]() .
(61)
.
(61)
Для практических расчетов при
определении числа контрольных разрядов кодов с минимальным кодовым расстоянием ![]() удобно пользоваться
выражениями:
удобно пользоваться
выражениями:
![]() (62)
(62)
если известна длина полной кодовой комбинации п, и
![]() (63)
(63)
если при расчетах удобнее
исходить из заданного числа информационных символов ![]() [10].
[10].
Для кодов, обнаруживающих все
трехкратные ошибки ![]()
![]() (64)
(64)
или
![]()
![]() (65)
(65)
Для кодов длиной в п
символов, исправляющих одну или две ошибки ![]()
![]() (66)
(66)
Для практических расчетов можно пользоваться выражением
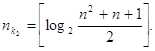 (67)
(67)
Для кодов, исправляющих 3 ошибки ![]()
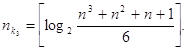 (68)
(68)
Для
кодов, исправляющих s ошибок ![]()
![]() (69)
(69)
Выражение слева известно как нижняя граница Хэмминга [16], а выражение справа – как верхняя граница Варшамова – Гильберта [3][11]
Для приближенных расчетов можно пользоваться выражением
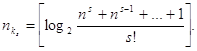 (70)
(70)
Можно
предположить, что значение ![]() будет приближаться к
верхней границе в зависимости от того, насколько выражение под знаком логарифма
приближается к целой степени двух.
будет приближаться к
верхней границе в зависимости от того, насколько выражение под знаком логарифма
приближается к целой степени двух.
Линейные групповые коды
Линейными называются коды, в которых проверочные символы представляют собой линейные комбинации информационных символов.
Для двоичных кодов в качестве линейной операции используют сложение по модулю 2.
Правила сложения по модулю 2 определяются следующими равенствами:
![]()
Последовательность нулей и единиц, принадлежащих данному коду, будем называть кодовым вектором.
Свойство линейных кодов: сумма (разность) кодовых векторов линейного кода дает вектор, принадлежащий данному коду.
Линейные коды образуют алгебраическую группу по отношению к операции сложения по модулю 2. В этом смысле они являются групповыми кодами.
Свойство группового кода: минимальное кодовое расстояние между кодовыми векторами группового кода равно минимальному весу ненулевых кодовых векторов.
Вес кодового вектора (кодовой комбинации) равен числу его ненулевых компонентов.
Расстояние между двумя кодовыми векторами равно весу вектора, полученного в результате сложения исходных векторов по модулю 2. Таким образом, для данного группового кода
![]() .
.
Групповые коды удобно задавать матрицами, размерность
которых определяется параметрами кода ![]() и
и
![]() . Число строк
матрицы равно
. Число строк
матрицы равно ![]() , число столбцов
равно
, число столбцов
равно ![]() +
+![]() =
=![]() :
:
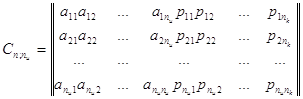 (71)
(71)
Коды, порождаемые этими
матрицами, известны как ![]() -коды,
где
-коды,
где ![]() , а соответствующие
им матрицы называют порождающими, производящими, образующими.
, а соответствующие
им матрицы называют порождающими, производящими, образующими.
Порождающая матрица С может
быть представлена двумя матрицами И и П (информационной и проверочной). Число
столбцов матрицы П равно ![]() ,
число столбцов матрицы И равно
,
число столбцов матрицы И равно ![]() :
:
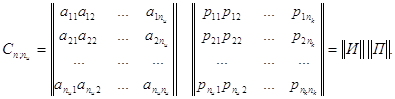 (72)
(72)
Теорией и практикой установлено, что в качестве матрицы И удобно брать единичную матрицу в канонической форме:
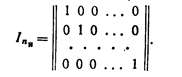
При выборе матрицы П исходят из следующих соображений: чем больше единиц в разрядах проверочной матрицы П, тем ближе соответствующий порождаемый код к оптимальному[12], с другой стороны, число единиц в матрице П определяет число сумматоров по модулю 2 в шифраторе и дешифраторе, т. е. чем больше единиц в матрице П, тем сложнее аппаратура.
Вес каждой строки матрицы П должен быть не менее ![]() , где
, где ![]() - вес соответствующей строки
матрицы И. Если матрица И - единичная, то
- вес соответствующей строки
матрицы И. Если матрица И - единичная, то
![]() (удобство выбора в качестве
матрицы И единичной матрицы очевидно: при
(удобство выбора в качестве
матрицы И единичной матрицы очевидно: при ![]() усложнилось бы как построение
кодов, так и их техническая реализация).
усложнилось бы как построение
кодов, так и их техническая реализация).
При соблюдении перечисленных условий любую порождающую матрицу группового кода можно привести к следующему виду:
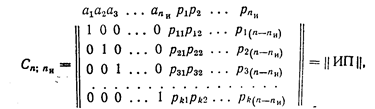
называемому левой канонической формой порождающей матрицы.
Для кодов с ![]() =2 производящая матрица С
имеет вид
=2 производящая матрица С
имеет вид
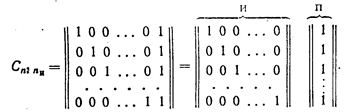
Во всех комбинациях кода, построенного при помощи такой матрицы, четное число единиц.
Для кодов с ![]() порождающая матрица не может
быть представлена в форме, общей для всех кодов с данным
порождающая матрица не может
быть представлена в форме, общей для всех кодов с данным ![]() . Вид матрицы зависит от
конкретных требований к порождаемому коду. Этими требованиями могут быть либо
минимум корректирующих разрядов, либо максимальная простота аппаратуры.
. Вид матрицы зависит от
конкретных требований к порождаемому коду. Этими требованиями могут быть либо
минимум корректирующих разрядов, либо максимальная простота аппаратуры.
Корректирующие коды с минимальным количеством избыточных разрядов называют плотно упакованными или совершенными кодами.
Для кодов с ![]() соотношения п и
соотношения п и ![]() . следующие: (3; 1),
(7;4), (15; 11), (31; 26), (63; 57) и т. д.
. следующие: (3; 1),
(7;4), (15; 11), (31; 26), (63; 57) и т. д.
Плотно упакованные коды,
оптимальные с точки зрения минимума избыточных символов, обнаруживающие
максимально возможное количество вариантов ошибок кратностью r + 1; r + 2 и т. д. и имеющие ![]() и
и ![]() ,
были исследованы Д. Слепяном в работе [10]. Для получения этих кодов матрица П
должна иметь комбинации с максимальным весом. Для этого при построении кодов с
,
были исследованы Д. Слепяном в работе [10]. Для получения этих кодов матрица П
должна иметь комбинации с максимальным весом. Для этого при построении кодов с ![]() последовательно используются
векторы длиной п
последовательно используются
векторы длиной п![]() , весом
, весом ![]() . Тем же Слепяном в работе [11]
были исследованы неплотно упакованные коды с малой плотностью проверок на
четность. Эти коды экономны с точки зрения простоты аппаратуры и содержат
минимальное число единиц в корректирующих разрядах порождающей матрицы. При
построении кодов с максимально простыми шифраторами и дешифраторами
последовательно выбираются векторы весом
. Тем же Слепяном в работе [11]
были исследованы неплотно упакованные коды с малой плотностью проверок на
четность. Эти коды экономны с точки зрения простоты аппаратуры и содержат
минимальное число единиц в корректирующих разрядах порождающей матрицы. При
построении кодов с максимально простыми шифраторами и дешифраторами
последовательно выбираются векторы весом ![]() = 2, 3, ...,
= 2, 3, ..., ![]() . Если число комбинаций, представляющих собой
корректирующие разряды кода и удовлетворяющих условию
. Если число комбинаций, представляющих собой
корректирующие разряды кода и удовлетворяющих условию ![]() , больше
, больше ![]() , то в первом случае не используют наборы с наименьшим весом, а во
втором - с наибольшим.
, то в первом случае не используют наборы с наименьшим весом, а во
втором - с наибольшим.
Строчки образующей матрицы С представляют собой ![]() комбинаций искомого кода.
Остальные комбинации кода строятся при помощи образующей матрицы по следующему
правилу: корректирующие символы, предназначенные для обнаружения или
исправления ошибки в информационной части кода, находятся путем суммирования по
модулю 2 тех строк матрицы П, номера которых совпадают с номерами разрядов,
содержащих единицы в кодовом векторе, представляющем информационную часть кода.
Полученную комбинацию приписывают справа к информационной части кода и получают
вектор полного корректирующего кода. Аналогичную процедуру проделывают со
второй, третьей и последующими информационными кодовыми комбинациями, пока не
будет построен корректирующий код для передачи всех символов первичного
алфавита.
комбинаций искомого кода.
Остальные комбинации кода строятся при помощи образующей матрицы по следующему
правилу: корректирующие символы, предназначенные для обнаружения или
исправления ошибки в информационной части кода, находятся путем суммирования по
модулю 2 тех строк матрицы П, номера которых совпадают с номерами разрядов,
содержащих единицы в кодовом векторе, представляющем информационную часть кода.
Полученную комбинацию приписывают справа к информационной части кода и получают
вектор полного корректирующего кода. Аналогичную процедуру проделывают со
второй, третьей и последующими информационными кодовыми комбинациями, пока не
будет построен корректирующий код для передачи всех символов первичного
алфавита.
Алгоритм образования проверочных символов по известной информационной части кода может быть записан следующим образом:
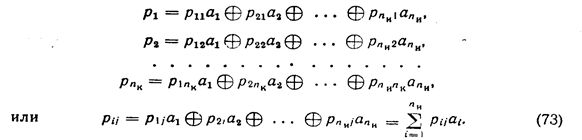
В процессе декодирования осуществляются проверки, идея которых в общем виде может быть представлена следующим образом:
![]()
Для каждой конкретной матрицы существует своя,
одна-единственная система проверок. Проверки производятся по следующему
правилу: в первую проверку вместе с проверочным разрядом ![]() входят информационные разряды,
которые соответствуют единицам первого столбца проверочной матрицы П; во вторую
проверку входит второй проверочный разряд
входят информационные разряды,
которые соответствуют единицам первого столбца проверочной матрицы П; во вторую
проверку входит второй проверочный разряд ![]() и
информационные разряды, соответствующие единицам второго столбца проверочной
матрицы, и т. д. Число проверок равно числу проверочных разрядов
корректирующего кода
и
информационные разряды, соответствующие единицам второго столбца проверочной
матрицы, и т. д. Число проверок равно числу проверочных разрядов
корректирующего кода ![]() .
.
В результате осуществления проверок образуется проверочный
вектор![]() , который называют синдромом.
Если вес синдрома равен нулю, то принятая комбинация считается безошибочной.
Если хотя бы один разряд проверочного вектора содержит единицу, то принятая
комбинация содержит ошибку. Исправление ошибки производится по виду синдрома,
так как каждому ошибочному разряду соответствует один-единственный проверочный
вектор.
, который называют синдромом.
Если вес синдрома равен нулю, то принятая комбинация считается безошибочной.
Если хотя бы один разряд проверочного вектора содержит единицу, то принятая
комбинация содержит ошибку. Исправление ошибки производится по виду синдрома,
так как каждому ошибочному разряду соответствует один-единственный проверочный
вектор.
Вид синдрома для каждой конкретной матрицы может быть
определен при помощи проверочной матрицы Н, которая представляет собой
транспонированную матрицу П, дополненную единичной матрицей ![]() , число столбцов которой равно
числу проверочных разрядов кода:
, число столбцов которой равно
числу проверочных разрядов кода:
![]() .
.
Столбцы такой матрицы представляют собой значение синдрома для разряда, соответствующего номеру столбца матрицы Н.
Процедура исправления ошибок в процессе декодирования групповых кодов сводится к следующему.
Строится кодовая таблица. В
первой строке таблицы располагаются все кодовые векторы ![]() . В первом столбце второй строки
размещается вектор
. В первом столбце второй строки
размещается вектор ![]() , вес
которого равен 1.
, вес
которого равен 1.
Остальные позиции второй строки
заполняются векторами, полученными в результате суммирования по модулю 2
вектора ![]() c вектором
c вектором ![]() , расположенным в соответствующем
столбце первой строки. В первом столбце третьей строки записывается вектор
, расположенным в соответствующем
столбце первой строки. В первом столбце третьей строки записывается вектор ![]() , вес которого также
равен 1, однако, если вектор
, вес которого также
равен 1, однако, если вектор ![]() содержит
единицу в первом разряде, то
содержит
единицу в первом разряде, то ![]() - во втором. В остальные позиции
третьей строки записывают суммы
- во втором. В остальные позиции
третьей строки записывают суммы ![]() и
и ![]() .
.
Аналогично поступают до тех пор,
пока не будут просуммированы с векторами ![]() все
векторы
все
векторы ![]() , весом 1, с единицами в
каждом из п разрядов. Затем суммируются по модулю 2 векторы
, весом 1, с единицами в
каждом из п разрядов. Затем суммируются по модулю 2 векторы ![]() , весом 2, с
последовательным перекрытием всех возможных разрядов. Вес вектора
, весом 2, с
последовательным перекрытием всех возможных разрядов. Вес вектора ![]() определяет число исправляемых
ошибок. Число векторов
определяет число исправляемых
ошибок. Число векторов ![]() , определяется
возможным числом неповторяющихся синдромов и равно
, определяется
возможным числом неповторяющихся синдромов и равно ![]() (нулевая
комбинация говорит об отсутствии ошибки). Условие неповторяемости синдрома
позволяет по его виду определять один-единственный соответствующий ему вектор
(нулевая
комбинация говорит об отсутствии ошибки). Условие неповторяемости синдрома
позволяет по его виду определять один-единственный соответствующий ему вектор ![]() . Векторы
. Векторы ![]() , есть векторы
ошибок, которые могут быть исправлены данным групповым кодом.
, есть векторы
ошибок, которые могут быть исправлены данным групповым кодом.
По виду синдрома принятая комбинация
может быть отнесена к тому или иному смежному классу, образованному сложением
по модулю 2 кодовой комбинации ![]() с вектором ошибки
с вектором ошибки ![]() ,
т. е. к определенной строке кодовой табл. 6.1.
,
т. е. к определенной строке кодовой табл. 6.1.
