

 Реферат: Технические характеристики современных серверов
Реферат: Технические характеристики современных серверов
Режим вмешательства (чтение с намерением модификации - RWITM):(c)
Процессорный узел или узел в/в (читающий узел) коммутируется с другим процессорным узлом или узлом в/в. Этот режим используется тогда, когда при выполнении операция RWITM от механизма наблюдения поступает ответ, что данная строка находится в кэш-памяти другого узла и модифицирована. В этом случае данные, извлекаемые из строки кэша владельца, подаются только читающему узлу и не записываются в память.
Режим программируемого ввода/вывода (PIO): (d)
Процессорный узел коммутируется с узлом в/в. Это случай операций PIO, при котором данные обмениваются только между процессором и узлом в/в.
Режим в/в с отображением в памяти (memory mapped):
Главный узел коммутируется с узлами в/в (подчиненными узлами), вовлеченными в транзакцию. Это случай операций с памятью.
Параметры производительности
Вслед за установочной фазой транзакции (например, после установки адреса на адресной шине) данные могут пересылаться через коммутатор на полной скорости синхронизации. Это возможно благодаря организации соединению точка-точка, которое создается для каждой отдельной транзакции. Поэтому в дальнейшем какие-либо помехи отсутствуют. Возможно также выполнять параллельно несколько операций, например, множественный доступ к памяти или пересылки между кэшами.
Для того чтобы уменьшить задержку памяти, операции чтения начинаются до выполнения каких-либо действий по обеспечению глобальной когерентности на уровне системы. Ответы когерентности полностью синхронизированы, разрешаются за фиксированное время и поступают всегда прежде, чем будет захвачен разделяемый ресурс - шина памяти. Это помогает избежать ненужных захватов шины. Любые транзакции, которые не разрешаются когерентно за данное фиксированное время, позднее будут повторены системой.
Используемая в системе внутренняя частота синхронизации равна 75 МГц, что позволяет оценить уровень производительности разработанной архитектуры. Интерфейс физической памяти имеет ширину 32 байта и, учитывая арбитраж шины, позволяет пересылать 32 байта каждые 3 такта синхронизации. Это дает скорость передачи данных 800 Мбайт/с, поддерживаемую на уровне интерфейса памяти. Каждый порт ЦП имеет ширину 8 байт и способен передавать по 8 байт за такт, т.е. со скоростью 600 Мбайт/с. Следует отметить, что это скорость, достигаемая как при пересылке ЦП-память, так и при пересылке кэш-кэш. Скорость 800 Мбайт/с для памяти поддерживается с помощью буферов в коммутаторе, которые позволяют конвейеризовать несколько операций.
Поскольку несколько операций могут выполняться через коммутатор на полной скорости параллельно, то для оптимальной смеси операций (две пересылки из ЦП в память, плюс пересылка кэш-кэш), пропускная способность может достигать пикового значения 1400 Мбайт/с. Таким образом, максимальная пропускная способность будет варьироваться в диапазоне от 800 до 1400 Мбайт/с в зависимости от коэффициента попаданий кэш-памяти.
Когерентность кэш-памяти
Известно, что требования, предъявляемые современными процессорами к полосе пропускания памяти, можно существенно сократить путем применения больших многоуровневых кэшей. Проблема когерентности памяти в мультипроцессорной системе возникает из-за того, что значение элемента данных, хранящееся в кэш-памяти разных процессоров, доступно этим процессорам только через их индивидуальные кэши. При этом определенные операции одного из процессоров могут влиять на достоверность данных, хранящихся в кэшах других процессоров. Поэтому в подобных системах жизненно необходим механизм обеспечения когерентного (согласованного) состояния кэшей. С этой целью в архитектуре PowerScale используется стратегия обратной записи, реализованная следующим образом.
Вертикальная когерентность кэшей
Каждый процессор для своей работы использует двухуровневый кэш со свойствами охвата. Это означает, что кроме внутреннего кэша первого уровня (кэша L1), встроенного в каждый процессор PowerPC, имеется связанный с ним кэш второго уровня (кэш L2). При этом каждая строка в кэше L1 имеется также и в кэше L2. В настоящее время объем кэша L2 составляет 1 Мбайт на каждый процессор, а в будущих реализациях предполагается его расширение до 4 Мбайт. Сама по себе кэш-память второго уровня позволяет существенно уменьшить число обращений к памяти и увеличить степень локализации данных. Для повышения быстродействия кэш L2 построен на принципах прямого отображения. Длина строки равна 32 байт (размеру когерентной гранулированности системы). Следует отметить, что, хотя с точки зрения физической реализации процессора PowerPC, 32 байта составляют только половину строки кэша L1, это не меняет протокол когерентности, который управляет операциями кэша L1 и гарантирует что кэш L2 всегда содержит данные кэша L1.
Кэш L2 имеет внешний набор тегов. Таким образом, любая активность механизма наблюдения за когерентным состоянием кэш-памяти может быть связана с кэшем второго уровня, в то время как большинство обращений со стороны процессора могут обрабатываться первичным кэшем. Если механизм наблюдения обнаруживает попадание в кэш второго уровня, то он должен выполнить арбитраж за первичный кэш, чтобы обновить состояние и возможно найти данные, что обычно будет приводить к приостановке процессора. Поэтому глобальная память может работать на уровне тегов кэша L2, что позволяет существенно ограничить количество операций наблюдения, генерируемых системой в направлении данного процессора. Это, в свою очередь, существенно увеличивает производительность системы, поскольку любая операция наблюдения в направлении процессора сама по себе может приводить к приостановке его работы.
Вторичная когерентность кэш-памяти
Вторичная когерентность кэш-памяти требуется для поддержки когерентности кэшей L1&L2 различных процессорных узлов, т.е. для обеспечения когерентного состояния всех имеющихся в мультипроцессорной системе распределенных кэшей (естественно включая поддержку когерентной буферизации ввода/вывода как по чтению, так и по записи).
Вторичная когерентность обеспечивается с помощью проверки каждой транзакции, возникающей на шине MPB_SysBus. Такая проверка позволяет обнаружить, что запрашиваемая по шине строка уже кэширована в процессорном узле, и обеспечивает выполнение необходимых операций. Это делается с помощью тегов кэша L2 и логически поддерживается тем фактом, что L1 является подмножеством L2.
Протокол MESI и функция вмешательства
В рамках архитектуры PowerScale используется протокол MESI, который представляет собой стандартный способ реализации вторичной когерентности кэш-памяти. Одной из основных задач протокола MESI является откладывание на максимально возможный срок операции обратной записи кэшированных данных в глобальную память системы. Это позволяет улучшить производительность системы за счет минимизации ненужного трафика данных между кэшами и основной памятью. Протокол MESI определяет четыре состояния, в которых может находиться каждая строка каждого кэша системы. Эта информация используется для определения соответствующих последующих операций (рис. 4.4).
Состояние строки "Единственная" (Exclusive):
Данные этой строки достоверны в данном кэше и недостоверны в любом другом кэше. Данные не модифицированы по отношению к памяти.
Состояние строки "Разделяемая" (Shared):
Данные этой строки достоверны в данном кэше, а также в одном или нескольких удаленных кэшах.
Состояние строки "Модифицированная" (Modified):
Данные этой строки достоверны только в данном кэше и были модифицированы. Данные недостоверны в памяти.
Состояние строки "Недостоверная" (Invalid):
Достоверные данные не были найдены в данном кэше.
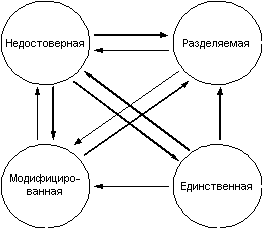
Рис. 4.4. Диаграмм переходов состояний протокола MESI
Для поддержки мультипроцессорной организации были реализованы несколько примитивов адресной шины. Это позволяет одному главному устройству шины передавать, а другим устройствам обнаруживать (или наблюдать) появление этих примитивов на шине. Устройство-владелец кэша наблюдает за адресной шиной во время глобального запроса и сравнивает целевой адрес с адресами тегов в своем кэше L2. Если происходит попадание, то выполняемые действия определяются природой запроса.
Как уже было отмечено, одной из функций тегов L2 является уменьшение накладных расходов, связанных с ответами на запросы механизма наблюдения. Доступ к тегам L2 разделяется между процессорами и адресной шиной. Теги L2 практически выполняют роль фильтров по отношению к активностям наблюдения. Это позволяет процессорам продолжать обработку вместо того, чтобы отвечать на каждый запрос наблюдения. Хотя теги L2 представляют собой разделяемый между процессором и шиной ресурс, его захват настолько кратковременен, что практически не приводит ни к каким конфликтам.
Состояние строки кэш-памяти "модифицированная" означает в частности то, что кэш, хранящий такие данные, несет ответственность за правильность этих данных перед системой в целом. Поскольку в основной памяти эти данные недостоверны, это означает, что владелец такого кэша должен каким-либо способом гарантировать, что никакой другой модуль системы не прочитает эти недостоверные данные. Обычно для описания такой ответственности используется термин "вмешательство" (intervention), которое представляет собой действие, выполняемое устройством-владельцем модифицированных кэшированных данных при обнаружении запроса наблюдения за этими данными. Вмешательство сигнализируется с помощью ответа состоянием "строка модифицирована" протокола MESI, за которым следуют пересылаемые запросчику, а также потенциально в память, данные.
Для увеличения пропускной способности системы в PowerScale реализованы два способа выполнения функции вмешательства:
- Немедленная кроссировка (Cross Immediate), которая используется когда канал данных источника и получателя свободны и можно пересылать данные через коммутатор на полной скорости.
- Поздняя кроссировка (Cross Late), когда ресурс (магистраль данных) занят, поэтому данные будут записываться в буфер коммутатора и позднее пересылаться запросчику.
Физическая реализация архитектуры
Ниже на рис. 4.5 показана схема, представляющая системные платы, разработанные компанией Bull, которые используются для физической реализации архитектуры PowerScale.
Многопроцессорная плата:
Многопроцессорная материнская плата, которая используется также в качестве монтажной панели для установки модулей ЦП, модулей основной памяти и одной платы в/в (IOD).
Модуль ЦП (дочерняя процессорная плата):
Каждый модуль ЦП, построенный на базе PowerPC 601/604, включает два микропроцессора и связанные с ними кэши. Имеется возможность модернизации системы, построенной на базе процессоров 601, путем установки модулей ЦП с процессорами 604. Смешанные конфигурации 601/604 не поддерживаются.
Дочерняя плата ввода/вывода: (IOD)
IOD работает в качестве моста между шинами MCA и комплексом ЦП и памяти. Поддерживаются 2 канала MCA со скоростью передачи 160 Мбайт/с каждый. Хотя поставляемая сегодня подсистема в/в базируется на технологии MCA, это не является принципиальным элементом архитектуры PowerScale. В настоящее время проводятся исследования возможностей реализации нескольких альтернативных шин ввода/вывода, например, PCI.
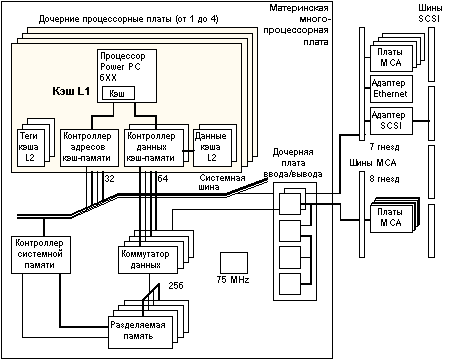
Рис. 4.5. Физическая реализация PowerScale
Платы памяти:
Каждая плата памяти состоит из четного числа банков. Максимальное число банков равно 16. Объем памяти на каждой плате может быть 64, 256 или 512 Мбайт.
Коммутатор данных (DCB) интегрирован в нескольких СБИС (4х16 бит) и функционально соединяет магистраль данных MPB_SysBus с подсистемой памяти, модулями ЦП и платой в/в. Ширина магистрали данных DCB на уровне массива памяти составляет 256 + 32 бит, а ширина магистрали данных для каждого порта ЦП и порта в/в равна 64 + 8 бит. Операции DCB управляются контроллером системной памяти (SMC) с помощью командной шины, обеспечивающей необходимую коммутацию устройств.
Семейство UNIX-серверов Escala
На российский рынок в настоящее время активно продвигаются UNIX-серверы семейства Escala - многопроцессорные системы с архитектурой PowerScale, построенные на базе микропроцессора PowerPC 601. Они предлагаются для работы в качестве нескольких типов серверов приложений: сервера транзакций (Transation Server) при использовании мониторов обработки транзакций подобных Tuxedo, сервера базы данных (Database Server) на основе таких известных систем как Oracle или Informix, а также управляющего сервера (System Management Server), обеспечивающего управление инфраструктурой предприятия и существенно упрощающего администрирование гетерогенными системами и сетями. Серверы Escala двоично совместимы с системами Bull DPX/20, а их архитектура разработана с учетом возможности применения новейших процессоров PowerPC 604 и 620.
Основные характеристики серверов Escala в зависимости от применяемого конструктива даны в таблице 4.1. Системы семейства Escala обеспечивают подключение следующих коммуникационных адаптеров: 8-, 16- и 128-входовых адаптеров асинхронных последовательных портов, 1- или 4-входовых адаптеров портов 2 Мбит/с X.25, а также адаптеров Token-Ring, Ethernet и FDDI.
Таблица 4.1
|
МОДЕЛЬ Escala |
M101 |
M201D201 D401 R201 |
|
Mini-Tower | DesksideRack-Mounted |
| ЦП | ||
| Тип процессора | PowerPC 601 | |
| Тактовая частота (МГц) | 75 | 7575 75 75 |
| Число процессоров | 1/4 | 2/42/8 4/8 2/8 |
| Размер кэша второго уровня (Кб) | 512 | 5121024 1024 1024 |
| ПАМЯТЬ | ||
| Стандартный объем (Мб) | 32 | 6464 64 64 |
| Максимальный объем (Мб) | 512 | 5122048 2048 2048 |
| ВВОД/ВЫВОД | ||
| Тип шины | MCA | MCAMCA MCA MCA |
| Пропускная способность (Мб/с) | 160 | 160160 2x160 2x160 |
| Количество слотов | 6 | 615 15 16 |
| Количество посадочных мест |
|
|
| 3.5" | 4 | 47 7 7 |
| 5.25" | 2 | 23 3 3 |
|
Емкость внутренней |
1/18 | 1/182/36 4/99 - |
|
Емкость внешней |
738 | 7381899 1899 2569 |
| Количество сетевых адаптеров | 1/4 | 1/41/12 1/12 1/13 |
| ПРОИЗВОДИТЕЛЬНОСТЬ (число процессоров 2/4) | ||
| SPECint92 | 77 | 7777 77 77 |
| SPECfp92 | 84 | 8484 84 84 |
| SPECrate_int92 | 3600/6789 | 3600/67893600/6789 - /6789 3600/6789 |
| SPECrate_fp92 | 3900/7520 | 3900/75203900/7520 - /7520 3900/7520 |
| Tpm-C | 750/1350 | 750/1350750/1350 750/1350 750/1350 |
Заключение
При разработке PowerScale Bull удалось создать архитектуру с достаточно высокими характеристиками производительности в расчете на удовлетворение нужд приложений пользователей сегодня и завтра. И обеспечивается это не только увеличением числа процессоров в системе, но и возможностью модернизации поколений процессоров PowerPC. Разработанная архитектура привлекательна как для разработчиков систем, так и пользователей, поскольку в ее основе лежит одна из главных процессорных архитектур в компьютерной промышленности - PowerPC.
