

 Реферат: Проектирование баз и хранилищ данных
Реферат: Проектирование баз и хранилищ данных
Особенности этого этапа развития выражаются в следующем:
Ø Все СУБД базируются на мощных мультипрограммных операционных системах (MVS, SVM, RTE, OSRV, RSX, UNIX), поэтому в основном поддерживается работа с централизованной базой данных в режиме распределенного доступа.
Ø Функции управления распределением ресурсов в основном осуществляются операционной системой (ОС).
Ø Поддерживаются языки низкого уровня манипулирования данными, ориентированные на навигационные методы доступа к данным.
Ø Значительная роль отводится администрированию данных.
Ø Проводятся серьезные работы по обоснованию и формализации реляционной модели данных, и была создана первая система (System R), реализующая идеологию реляционной модели данных.
Ø Проводятся теоретические работы по оптимизации запросов и управлению распределенным доступом к централизованной БД, было введено понятие транзакции.
Ø Результаты научных исследований открыто обсуждаются в печати, идет мощный поток общедоступных публикаций, касающихся всех аспектов теории и практики баз данных, и результаты теоретических исследований активно внедряются в коммерческие СУБД.
Появляются первые языки высокого уровня для работы с реляционной моделью данных. Однако отсутствуют стандарты для этих первых языков.
Второй этап - эпоха персональных компьютеров
Персональные компьютеры стремительно ворвались в нашу жизнь и буквально перевернули наше представление о месте и роли вычислительной техники в жизни общества. Теперь компьютеры стали ближе и доступнее каждому пользователю. Исчез благоговейный страх рядовых пользователей перед непонятными и сложными языками программирования. Появилось множество программ, предназначенных для работы неподготовленных пользователей. Эти программы были просты в использовании и интуитивно понятны: это, прежде всего, различные редакторы текстов, электронные таблицы и другие. Простыми и понятными стали операции копирования файлов и перенос информации с одного компьютера на другой, распечатка текстов, таблиц и других документов. Системные программисты были отодвинуты на торой план. Каждый пользователь мог себя почувствовать полным хозяином этого мощного и удобного устройства, позволяющего автоматизировать многие аспекты деятельности. И, конечно, это сказалось и на работе с базами данных. Появились программы, которые назывались системами управления базами данных и позволяли хранить значительные объемы информации, они имели удобный интерфейс для заполнения данных, встроенные средства для генерации различных отчетов. Эти программы позволяли автоматизировать многие учетные функции, которые раньше велись вручную. Постоянное снижение цен на персональные компьютеры сделало их доступными не только для организаций и фирм, но и для отдельных пользователей. Компьютеры стали инструментом для ведения документации и собственных учетных функций. Это все сыграло как положительную, так и отрицательную роль в области развития баз данных. Кажущаяся простота и доступность персональных компьютеров и их программного обеспечения породила множество дилетантов. Эти разработчики, считая себя знатоками, стали проектировать недолговечные базы данных, которые не учитывали многих особенностей объектов реального мира. Много было создано систем-однодневок, которые не отвечали законам развития и взаимосвязи реальных объектов. Однако доступность персональных компьютеров заставила пользователей из многих областей знаний, которые ранее не применяли вычислительную технику в своей деятельности, обратиться к ним. И спрос на развитые удобные программы обработки данных заставлял поставщиков программного обеспечения поставлять все новые системы, которые принято называть настольными (desktop) СУБД. Значительная конкуренция среди поставщиков заставляла совершенствовать эти системы, предлагая новые возможности, улучшая интерфейс и быстродействие систем, снижая их стоимость. Наличие на рынке большого числа СУБД, выполняющих сходные функции, потребовало разработки методов экспорта-импорта данных для этих систем и открытия форматов хранения данных.
Но и в этот период появлялись любители, которые вопреки здравому смыслу разрабатывали собственные СУБД, используя стандартные языки программирования. Это был тупиковый вариант, потому что дальнейшее развитие показало, что перенести данные из нестандартных форматов в новые СУБД было гораздо труднее, а в некоторых случаях требовало таких трудозатрат, что легче было бы все разработать заново, но данные все равно надо было переносить на новую более перспективную СУБД. И это тоже было результатом недооценки тех функций, которые должна была выполнять СУБД.
Особенности этого этапа следующие:
Ø Все СУБД были рассчитаны на создание БД в основном с монопольным доступом. И это понятно. Компьютер персональный, он не был подсоединен к сети, и база данных на нем создавалась для работы одного пользователя. В редких случаях предполагалась последовательная работа нескольких пользователей, например, сначала оператор, который вводил бухгалтерские документы, а потом главбух, который определял проводки, соответствующие первичным документам.
Ø Большинство СУБД имели развитый и удобный пользовательский интерфейс, В большинстве существовал интерактивный режим работы с БД, как в рамках описания БД, так и в рамках проектирования запросов. Кроме того, большинство СУБД предлагали развитый и удобный инструментарии для разработки готовых приложений без программирования. Инструментальная среда состояла из готовых элементов приложения в виде шаблонов экранных форм, отчетов, этикеток (Labels), графических конструкторов запросов, которые достаточно просто могли быть собраны в единый комплекс.
Ø Во всех настольных СУБД поддерживался только внешний уровень представления реляционной модели, то есть только внешний табличный вид структур данных.
Ø При наличии высокоуровневых языков манипулирования данными типа реляционной алгебры и SQL в настольных СУБД поддерживались низкоуровневые языки манипулирования данными на уровне отдельных строк таблиц.
Ø В настольных СУБД отсутствовали средства поддержки ссылочной и структурной целостности базы данных. Эти функции должны были выполнять приложения, однако скудость средств разработки приложений иногда не позволяла это сделать, и в этом случае эти функции должны были выполняться пользователем, требуя от него дополнительного контроля при вводе и изменении информации, хранящейся в БД.
Ø Наличие монопольного режима работы фактически привело к вырождению функций администрирования БД и в связи с этим — к отсутствию инструментальных средств администрирования БД.
Ø И, наконец, последняя и в настоящий момент весьма положительная особенность — это сравнительно скромные требования к аппаратному обеспечению со стороны настольных СУБД. Вполне работоспособные приложения, разработанные, например, на Clipper, работали на PC 286.
В принципе, их даже трудно назвать полноценными СУБД. Яркие представители этого семейства это очень широко использовавшиеся до недавнего времени СУБД dBase (dBase III+, dBase IV), FoxPro, Clipper, Paradox.
Третий этап - распределенные базы данных
Хорошо известно, что история развивается по спирали, поэтому после процесса «персонализации» начался обратный процесс — интеграция. Множится количество локальных сетей, все больше информации передастся между компьютерами, остро встает задача согласованности данных, хранящихся и обрабатывающихся в разных местах, но логически друг с другом связанных, возникают задачи, связанные с параллельной обработкой транзакций — последовательностей операций над БД, переводящих ее из одного непротиворечивого состояния в другое непротиворечивое состояние. Успешное решение этих задач приводит к появлению распределенных баз данных, сохраняющих все преимущества настольных СУБД и в то же время позволяющих организовать параллельную обработку информации и поддержку целостности БД.
Особенности данного этапа:
Ø Практически все современные СУБД обеспечивают поддержку полной реляционной модели, а именно:
· структурной целостности — допустимыми являются только данные, представленные в виде отношений реляционной модели;
· языковой целостности, то есть языков манипулирования данными высокого уровня (в основном SQL);
· ссылочной целостности — контроля за соблюдением ссылочной целостности в течение всего времени функционирования системы, и гарантий невозможности со стороны СУБД нарушить эти ограничения.
Ø Большинство современных СУБД рассчитаны на многоплатформенную архитектуру, то есть они могут работать на компьютерах с разной архитектурой и под разными операционными системами, при этом для пользователей доступ к данным, управляемым СУБД, на разных платформах практически неразличим.
Ø Необходимость поддержки многопользовательской работы с базой данных и возможность децентрализованного храпения данных потребовали развития средств администрирования БД с реализацией общей концепции средств защиты данных.
Ø Потребность в новых реализациях вызвала создание серьезных теоретических трудов по оптимизации реализации распределенных БД и работе с распределенными транзакциями и запросами с внедрением полученных результатов в коммерческие СУБД.
Ø Для того чтобы не потерять клиентов, которые ранее работали на настольных СУБД, практически все современные СУБД имеют средства подключения клиентских приложений, разработанных с использованием настольных СУБД, и средства экспорта данных из форматов настольных СУБД второго этапа развития.
К этому этапу можно отнести разработку ряда стандартов в рамках языков описания и манипулирования данными (SQL89, SQL92, SQL99) и технологий по обмену данными между различными СУБД, к которым можно отнести и протокол ODBC (Open DataBase Connectivity), предложенный фирмой Microsoft.
Именно к этому этапу можно отнести начало работ, связанных с концепцией объектно-ориентированных БД — ООБД. Представителями СУБД, относящимся ко второму этапу, можно считать MS Access 97 и все современные серверы баз данных Огас1е7.3, 0гас1е 8.4, MS SQL 6.5, MS SQL 7.0, System 10, System 11, Informix, DB2, SQL Base и другие современные серверы баз данных, которых в настоящий момент насчитывается несколько десятков.
Четвертый этап - перспективы развития систем управления базами данных
Этот этап характеризуется появлением новой технологии доступа к данным — интранет. Основное отличие этого подхода от технологии клиент-сервер состоит в том, что отпадает необходимость использования специализированного клиентского программного обеспечения. Для работы с удаленной базой данных используется стандартный броузер Internet, например Microsoft Internet Explorer или Netscape Navigator, и для конечного пользователя процесс обращения к данным происходит аналогично скольжению по Всемирной Паутине. При этом встроенный в загружаемые пользователем HTML-страницы код, написанный обычно на языках Java, Java-script, Perl и других, отслеживает все действия пользователя и транслирует их в низкоуровневые SQL-запросы к базе данных, выполняя, таким образом, ту работу, которой в технологии клиент-сервер занимается клиентская программа. Удобство данного подхода привело к тому, что он стал использоваться не только для удаленного доступа к базам данных, но и для пользователей локальной сети предприятия. Простые задачи обработки данных, не связанные со сложными алгоритмами, требующими согласованного изменения данных во многих взаимосвязанных объектах, достаточно просто и эффективно могут быть построены по данной архитектуре. В этом случае для подключения нового пользователя к возможности использовать данную задачу не требуется установка дополнительного клиентского программного обеспечения. Однако алгоритмически сложные задачи рекомендуется реализовывать в архитектуре «клиент-сервер» с разработкой специального клиентского программного обеспечения.
У каждого из вышеперечисленных подходов к работе с данными есть свои достоинства и свои недостатки, которые и определяют область применения того или иного метода, и в настоящее время все подходы широко используются.
Тема 2. Основные понятия и определения
Современные авторы часто употребляют термины – «банк данных» и «база данных» как синонимы, однако в общеотраслевых руководящих материалах по созданию банков данных Государственного комитета по науке и технике (ГКНТ), изданных в 1982 г., эти понятия различаются. Там приводятся следующие определения банка данных, базы данных и СУБД:
Банк данных (БнД) — это система специальным образом организованных данных — баз данных, программных, технических, языковых, организационно-методических средств, предназначенных для обеспечения централизованного накопления и коллективного многоцелевого использования данных.
База данных (БД) — именованная совокупность данных, отражающая состояние объектов и их отношений и рассматриваемой предметной области.
Под предметной областью понимают один или несколько объектов управления (или определенные их части), информация которых моделируется с помощью БД и используется для решения различных функциональных задач.
Система управления базами данных (СУБД) — совокупность языковых и программных средств, предназначенных для создания, ведения и совместного использования БД многими пользователями. В ней можно выделить:
- ядро СУБД, которое обеспечивает организацию ввода, обработки и хранения данных,
- компоненты, которые обеспечивают отладку системы, средства тестирования,
- утилиты, которые обеспечивают выполнение вспомогательных функций (например, ведение журнала статистики работы системы и др.).
Очень важной задачей СУБД является обеспечение независимости данных. Практически одна и одна и та же СУБД может быть использована для ведения абсолютно разных файлов, которые используются для решения разноплановых, не связанных между собою задач управления. Все функции СУБД можно объединить в такие группы:
1. Управление данными. Задачами управления данных является подготовка данных и их контроль, внесение данных в базу, структуризация данных, обеспечение целостности, секретности данных.
2. Доступ к данным. Поиск и селекция данных, преобразование данных в форму, удобную для дальнейшего использования.
3. Организация и ведение связи с пользователем. Ведение диалога, выдача диагностических сообщений об ошибках в работе по БД и т.д.
Для обработки запросов к БД разрабатывают программы, которые составляют прикладное программное обеспечение. Программы, с помощью которых пользователи работают с базой данных, называются приложениями. В общем случае с одной базой данных могут работать множество различных приложений. Например, если база данных моделирует некоторое предприятие, то для работы с ней может быть создано приложение, которое обслуживает подсистему учета кадров, другое приложение может быть посвящено работе подсистемы расчета заработной платы сотрудников, третье приложение работает как подсистема складского учета, четвертое приложение посвящено планированию производственного процесса. При рассмотрении приложений, работающих с одной базой данных, предполагается, что они могут работать параллельно и независимо друг от друга, и именно СУБД призвана обеспечить работу множества приложений с единой базой данных таким образом, чтобы каждое из них выполнялось корректно, но учитывало все изменения в базе данных, вносимые другими приложениями.
Языковые средства банка данных
Языковые средства СУБД, необходимые для описания данных, организации общения и выполнения процедур поиска и различных преобразований данных. Классификация языковых средств БнД, показанная на рис. 2.2, разработана американским комитетом CODASYL по проектированию и созданию БД.
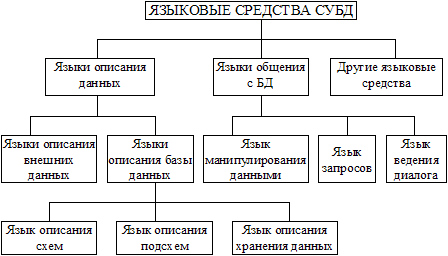
Рис.2.2. Схема классификации языковых средств БнД
Схема имеет общий характер и ориентирована на различные СУБД. Однако не каждая СУБД, которая сейчас используется на практике и распространена на рынке программных продуктов, имеет весь набор указанных языковых средств.
Язык описания данных (DDL - Data Definition Language), предназначен для описания данных на разных уровнях абстракции: внешнем, логическом и внутреннем. Исходя из предложений CODASYL, языки описания данных на логическом (концептуальном) и внутреннем уровнях независимые и разные. Однако в большинстве промышленных СУБД языки не делится на два отдельных языка описания логической и физической организации данных, а существует единый язык, которая еще называется языком описания схем. В известных и широко используемых на практике СУБД семьи dBASE применяется единый язык описания данных. Он предназначен для представления данных на логическом и физическом уровнях. Этот язык имеет свой синтаксис: например, имя файла не должно превышать восьми символов, а имя поля - десяти; при этом каждое имя может начинаться с буквы, поля календарной даты обозначаются символом D (DATA), символьные поля — С (CHARACTER), числовые — N (NUMERIC), логические — L (LOGICAL), примечаний — М (MEMO).
