

 Реферат: Подсистема памяти современных компьютеров
Реферат: Подсистема памяти современных компьютеров
Очень часто организация кэш-памяти в разных машинах отличается именно стратегией выполнения записи. Когда выполняется запись в кэш-память имеются две базовые возможности:
сквозная запись (write through, store through) - информация записывается в два места: в блок кэш-памяти и в блок более низкого уровня памяти.
запись с обратным копированием (write back, copy back, store in) - информация записывается только в блок кэш-памяти. Модифицированный блок кэш-памяти записывается в основную память только когда он замещается. Для сокращения частоты копирования блоков при замещении обычно с каждым блоком кэш-памяти связывается так называемый бит модификации (dirty bit). Этот бит состояния показывает был ли модифицирован блок, находящийся в кэш-памяти. Если он не модифицировался, то обратное копирование отменяется, поскольку более низкий уровень содержит ту же самую информацию, что и кэш-память.
Оба подхода к организации записи имеют свои преимущества и недостатки. При записи с обратным копированием операции записи выполняются со скоростью кэш-памяти, и несколько записей в один и тот же блок требуют только одной записи в память более низкого уровня. Поскольку в этом случае обращения к основной памяти происходят реже, вообще говоря требуется меньшая полоса пропускания памяти, что очень привлекательно для мультипроцессорных систем. При сквозной записи промахи по чтению не влияют на записи в более высокий уровень, и, кроме того, сквозная запись проще для реализации, чем запись с обратным копированием. Сквозная запись имеет также преимущество в том, что основная память имеет наиболее свежую копию данных. Это важно в мультипроцессорных системах, а также для организации ввода/вывода.
Когда процессор ожидает завершения записи при выполнении сквозной записи, то говорят, что он приостанавливается для записи (write stall). Общий прием минимизации остановов по записи связан с использованием буфера записи (write buffer), который позволяет процессору продолжить выполнение команд во время обновления содержимого памяти. Следует отметить, что остановы по записи могут возникать и при наличии буфера записи.
При промахе во время записи имеются две дополнительные возможности:
разместить запись в кэш-памяти (write allocate) (называется также выборкой при записи (fetch on write)). Блок загружается в кэш-память, вслед за чем выполняются действия аналогичные выполняющимся при выполнении записи с попаданием. Это похоже на промах при чтении.
не размещать запись в кэш-памяти (называется также записью в окружение (write around)). Блок модифицируется на более низком уровне и не загружается в кэш-память.
Обычно в кэш-памяти, реализующей запись с обратным копированием, используется размещение записи в кэш-памяти (в надежде, что последующая запись в этот блок будет перехвачена), а в кэш-памяти со сквозной записью размещение записи в кэш-памяти часто не используется (поскольку последующая запись в этот блок все равно пойдет в память).
Вполне понятно, что производительность компьютера непосредственно зависит от производительности процессора и производительности оперативной памяти. Теоретическая производительность (пропускная способность) памяти пропорциональна разрядности и тактовой частоте шины и обратно пропорциональна суммарной длительности пакетного цикла. Для повышения этой производительности увеличивают разрядность шины (так, начиная с P5 32-разрядные процессоры имеют 64-разрядную системную шину), тактовую частоту (с 66 МГц наконец-то поднялись до 100 с прицелом на 133 МГц). При этом, естественно, стремятся и к уменьшению числа тактов в пакетном цикле. Кроме того, шина P6 позволяет процессору выставить до 16 запросов конкурирующих транзакций, так что у подсистемы памяти есть теоретическая возможность “многостаночной” работы.
Динамическая память
Теперь посмотрим на оперативную память изнутри. На протяжении уже трех десятилетий в качестве основной памяти используют массивы ячеек динамической памяти. Каждая ячейка содержит всего лишь один КМОП-транзистор (комплементарные полевые траезисторы), благодаря чему достигается высокая плотность упаковки ячеек при низкой цене. Запоминающим элементом у них является конденсатор (емкость затвора), и ячейка может помнить свое состояние недолго — всего десятки миллисекунд. Для длительного хранения требуется регенерация — регулярное “освежение” (refresh) памяти, за что эта память и получила название “динамическая” — DRAM (Dynamic RAM). Ячейки организуются в двумерные матрицы, и для обращения к ячейке требуется последовательно подать два выбирающих сигнала — RAS# (Row Access Strobe, строб строки) и CAS# (Column Access Strobe, строб столбца). Временная диаграмма циклов чтения традиционной динамической памяти приведена на рисунке (циклы записи для простоты здесь рассматривать не будем). Микросхемы динамической памяти традиционно имеют мультиплексированную шину адреса (MA). Во время действия RAS# на ней должен быть адрес строки, во время действия CAS# — адрес столбца. Информация на выходе шины данных относительно начала цикла (сигнала RAS#) появится не раньше, чем через интервал TRAC, который называется временем доступа. Есть также минимальная задержка данных относительно импульса CAS# (TCAC), и минимально необходимые интервалы пассивности сигналов RAS# и CAS# (времена предзаряда). Все эти параметры и определяют предел производительности памяти. Ключевой параметр микросхем — время доступа — за всю историю удалось улучшить всего на порядок — с сотен до нескольких десятков наносекунд. За меньший исторический период только тактовая частота процессоров x86 выросла на 2 порядка, так что разрыв между потребностями процессоров и возможностями ячеек памяти увеличивается. Для преодоления этого разрыва, во-первых, увеличивают разрядность данных памяти, а во-вторых, строят вокруг массивов ячеек памяти разные хитрые оболочки, ускоряющие процесс доступа к данным. Все, даже “самые модные”, типы памяти — SDRAM, DDR SDRAM и Rambus DRAM имеют запоминающее ядро, которое обслуживается описанным выше способом.
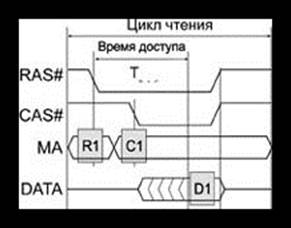
Временная диаграмма чтения динамической памяти
Общий принцип доступа к данным
Массив данных представляет собой некое подобие координатной сетки, где есть положения по горизонтали (адрес строки) и по вертикали (адрес столбца). На пересечении каждого конкретного адреса строки и столбца находится единичный «строительный элемент» памяти – ячейка, которая представляет собой ключ (транзистор) и запоминающий элемент (конденсатор). Например, для чтения или записи одной ячейки памяти необходимо пять тактов. Сначала на шину выставляется адрес строки. Затем подается сигнал RAS#, который является своего рода контрольным сигналом, передающим полученный адрес для записи в специально отведенное место – регистр микросхемы памяти. После этого передается сигнал столбца, следующим тактом за которым идет сигнал подтверждения принимаемого адреса, но уже для столбца – CAS#. И, наконец следует операция чтения-записи в/из ячейки, контролируемая сигналом разрешения – WE#. Однако, если считываются соседние ячейки, то тогда нет необходимости передавать каждый раз адрес строки или столбца – процессор «надеется», что считываемые данные расположены по соседству. Поэтому, на считывание каждой последующей ячейки понадобится уже 3 такта системной шины. Отсюда и берут свое начало существование определенных схем функционирования (тайминги) отдельно взятой разновидности памяти: x-yyy-yyyy-..., где "x" – количество тактов шины, необходимое для чтение первого бита, а у – для всех последующих. Так, цикл доступа процессора к памяти состоит из двух фаз: запроса (Request) и ответа (Response). Фаза запроса состоит из трех действий: подача адреса, подача запроса (чтения-записи) и подтверждение (необязательно). В фазу ответа входит выдача запрашиваемых данных и подтверждение приема. Довольно часто происходит чтение четырех смежных ячеек, поэтому многие типы памяти специально оптимизированы для данного режима работы, и в сравнительных характеристиках быстродействия обычно приводится только количество циклов, необходимое для чтения первых четырех ячеек. Здесь речь идет о пакетной передаче, которая подразумевает подачу одного начального адреса и дальнейшую выборку по ячейкам в установленном порядке. Такого рода передача улучшает скорость доступа к участкам памяти с заранее определенными последовательными адресами. Обычно процессор вырабатывает адресные пакеты на четыре передачи данных по шине, поскольку предполагается, что система автоматически возвратит данные из указанной ячейки и трех следующих за ней. Преимущество такой схемы очевидно – на передачу четырех порций данных требуется всего одна фаза запроса. Например, для памяти типа FPM DRAM применяется самая простая схема 5-333-3333-... Для памяти типа EDO DRAM после первого считывания блока данных, увеличивается время доступности данных того ряда, к которому происходит доступ в настоящий момент, при этом уменьшая время получения пакета данных, и память уже может работать по схеме 5-222-2222-... Синхронная память типа SDRAM, в отличие от асинхронной (FPM и EDO), «свободна» от передачи в процессор сигнала подтверждения, и выдает и принимает данные в строго определенные моменты времени (только совместно с сигналом синхронизации системной шины), что исключает несогласованность между отдельными компонентами, упрощает систему управления и дает возможность перейти на более «короткую» схему работы: 5-111-1111-... Поэтому в рассматриваемом пункте меню настройки можно встретить варианты допустимых значений для циклов обращения к памяти: x333 или x444 – оптимально подходит для FPM DRAM, x222 или x333 – для EDO DRAM, и x111 или x222 – для SDRAM.
Традиционная память с асинхронным интерфейсом
В традиционной памяти сигналы RAS# и CAS#, обслуживающие запоминающие ячейки, вводятся непосредственно по соответствующим линиям интерфейса. Вся последовательность процессов в памяти привязывается именно к этим внешним сигналам. Данных при чтении будут готовы через время TCAC после сигнала RAS#, но не раньше, чем через TRAC после сигнала RAS#.
На основе стандартных ячеек строится память с быстрым страничным доступом — FPM (Fast Page Mode) DRAM. Здесь для доступа к ячейкам, расположенным в разных колонках одной строки, используется всего один импульс RAS#, во время которого выполняется серия обращений с помощью только импульсов CAS#. Нетрудно догадаться, что в пакетных циклах доступа получается выигрыш во времени (пакеты укладываются в страницы “естественным” образом). Так, память FPM со временем доступа 60–70 нс при частоте шины 66 МГц может обеспечить цикл чтения 5-3-3-3.
Следующим шагом стала память EDO (Extended Data Out, расширенный вывод данных) DRAM. Здесь в микросхемы памяти ввели регистры-защелки, и считываемые данные присутствуют на выходе даже после подъема CAS#. Благодаря этому можно сократить время действия CAS# и не дожидаясь, пока внешняя схема примет данные, приступить к предзаряду линии CAS#. Таким образом можно ускорить передачу данных внутри пакета и на тех же ячейках памяти получить цикл 5-2-2-2 (60 нс, 66 МГц). Эффект полученного ускорения компьютера, полученного довольно простым способом, был эквивалентен введению вторичного кэша, что и послужило поводом для мифа о том, что “в EDO встроен кэш”. Страничный цикл для памяти EDO называют и “гиперстраничным”, так что второе название у этой памяти — HPM (Hyper Page Mode) DRAM. Регистр-защелка ввел в микросхему памяти элемент конвейера — импульс CAS# передает данные на эту ступень, а пока внешняя схема считывает их, линия CAS# готовится к следующему импульсу.
Память BEDO (Burst EDO, пакетная EDO) DRAM ориентирована на пакетную передачу. Здесь полный адрес (со стробами RAS# и CAS#) подается только в начале пакетного цикла; последующие импульсы CAS# адрес не стробируют, а только выводят данные — память уже “знает”, какие следующие адреса потребуются в пакете. Результат — при тех же условиях цикл 5-1-1-1.
Память EDO появилась во времена Pentium и стала применяться также в системах на 486. Она вытеснила память FPM и даже стала ее дешевле. Память BEDO широкого распространения не получила, поскольку ей уже “наступала на пятки” синхронная динамическая память.
Вышеперечисленные типы памяти являются асинхронными по отношению к тактированию системной шины компьютера. Это означает, что все процессы инициируются только импульсами RAS# и CAS#, а завершаются через какой-то определенный (для данных микросхем) интервал. На время этих процессоров шина памяти оказывается занятой, причем, в основном, ожиданием данных.
Память с синхронным интерфейсом — SDRAM и DDR SDRAM
Для вычислительного конвейера, в котором могут параллельно выполняться несколько процессов и запросов к данным, гораздо удобнее синхронный интерфейс. В этом случае все события привязываются к фронтам общего сигнала синхронизации, и система четко “знает”, что, выставив запрос на данные в таком-то такте, она получит их через определенное число тактов. А между этими событиями на шину памяти можно выставить и другой запрос, и если он адресован к свободному банку памяти, начнется скрытая (latency) фаза его обработки. Таким образом удается повысить производительность подсистемы памяти и ее шины, причем не за счет безумного увеличения числа проводов (увеличения разрядности и числа независимых банков, о чем будет сказано позже).
Микросхемы синхронной динамической памяти SDRAM (Synchronous DRAM) представляет собой конвейеризированные устройства, которые на основе вполне обычных ячеек (время доступа — 50–70 нс) обеспечивают цикл 5-1-1-1, но уже при частоте шины 100 МГц и выше. По составу сигналов интерфейс SDRAM близок к обычной динамической памяти: кроме входов синхронизации, здесь есть мультиплексированная шина адреса, линии RAS#, CAS#, WE (разрешение записи) и CS (выбор микросхемы) и, конечно же, линии данных. Все сигналы стробируются по положительному перепаду синхроимпульсов, комбинация управляющих сигналов в каждом такте кодирует определенную команду. С помощью этих команд организуется та же последовательность внутренних сигналов RAS# и CAS#, которая рассматривалась и для памяти FPM.
Каждая микросхема внутренне может быть организована как набор из 4 банков с собственными независимыми линиями RAS#. Для начала любого цикла обращения к памяти требуется подать команду ACT, которая запускает внутренний формирователь RAS# для требуемой строки выбранного банка. Спустя некоторое количество тактов можно вводить команду чтения RD или записи WR, в которой передается номер столбца первого цикла пакета. По этой команде запускается внутренний формирователь CAS#. Передача данных для циклов записи и чтения различается. Данные для первой передачи пакета записи устанавливаются вместе с командой WR. В следующих тактах подаются данные для остальных передач пакета. Первые данные пакета чтения появляются на шине через определенное количество тактов после команды. Это число, называемое CAS# Latency (CL), определяется временем доступа TCAC и тактовой частотой. В последующих тактах будут выданы остальные данные пакета. После обращения необходимо деактивировать банк — перевести внутренний сигнал RAS# в пассивное состояние, то есть произвести предзаряд (precharge). Это может быть сделано либо явно командой PRE, либо автоматически (как модифицированный вариант команд RD или WR. Внутренние сигналы CAS# формируются автоматически по командам обращения и дополнительных забот не требуют.
Регенерация выполняется по команде REF, за заданный период регенерации (стандартный 64 мс) должно быть выполнено 4096 или 8192 (в зависимости от объема микросхемы) команд REF.
На первый взгляд из этого описания не видно никаких особых преимуществ SDRAM по сравнению с BEDO. Однако синхронный интерфейс в сочетании с внутренней мультибанковой организацией обеспечивает возможность повышения производительности памяти при множественных обращениях. Здесь имеется в виду способность современных процессоров формировать следующие запросы к памяти, не дожидаясь результатов выполнения предыдущих. В SDRAM после выбора строки (активации банка) ее можно закрывать не сразу, а после выполнения серии обращений к ее элементам, причем как по записи, так и по чтению. Эти обращения будут выполняться быстрее, поскольку для них не требуется подачи команды активации и выжидания TRCD. Максимальное время удержания строки открытой ограничивается периодом регенерации. Возможность работы с открытой строкой была использована уже в FPM DRAM. Однако в SDRAM можно активировать строки в нескольких банках — каждую своей командой ACT, эта особенность и стоит за словами “Single-pulsed RAS# interface” в перечислении ключевых особенностей SDRAM. Активировать строку можно во время выполнения любой операции с другим банком. Обращение к открытой строке требуемого банка выполняется по командам RD и WR, у которых в качестве параметров кроме адреса столбца фигурирует и номер банка. Таким образом можно так спланировать транзакции, что шина данных в каждом такте будет нести очередную порцию данных, и такой поток будет продолжаться не только в пределах одного пакета, но и для серии обращений к разным областям памяти. Кстати, держать открытыми можно и строки в банках разных микросхем, объединенных общей шиной памяти.
