

 Реферат: Классификация сейсмических сигналов на основе нейросетевых технологий
Реферат: Классификация сейсмических сигналов на основе нейросетевых технологий
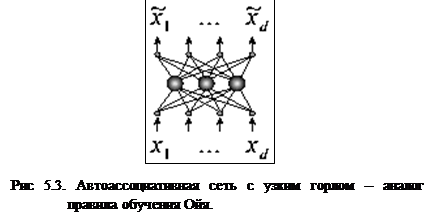
Чтобы восстановить свои входные данные, сеть должна научиться представлять их в более низкой размерности. Базовый алгоритм обучения в этом случае носит название правило обучения Ойя для однослойной сети. Учитывая то, что в такой структуре веса с одинаковыми индексами в обоих слоях одинаковы, дельта-правило обучения верхнего (а тем самым и нижнего) слоя можно записать в виде:
![]() , где
, где
![]()
![]() ,и
,и
![]()
![]() ,
,
![]() , j=1,2,…,d – компонента входного вектора;
, j=1,2,…,d – компонента входного вектора;
![]() , выходы сети j=1,…,d;
, выходы сети j=1,…,d;
d - количество нейронов на входном ми выходном слоях (размерность вектора признаков);
yi - выход с i-го нейрона внутреннего слоя, i=1,…,M
M – количество нейронов на внутреннем слое;
h - коэффициент обучения;
wij=wkj - веса сети , соответственно между входным – скрытым и скрытым – выходным слоями.
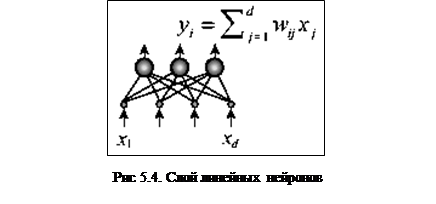
Скрытый слой такой сети осуществляет оптимальное кодирование входных данных, и содержит максимально возможное при данных ограничениях количество информации. После обучения внешний интерфейс (wij) (рис.5.4) может быть сохранен и использован для понижения размерности.
Нелинейный анализ главных компонент.
Главное преимущество нейроалгоритмов в том, что они легко обобщаются на случай нелинейного сжатия информации, когда никаких явных решений уже не существует. Можно заменить линейные нейроны в описанных выше сетях – нелинейными. С минимальными видоизменениями нейроалгоритмы будут работать и в этом случае, всегда находя оптимальное сжатие информации при наложенных ограничениях. Например, простая замена линейной функции активации нейронов на сигмоидную в правиле обучения Ойя:
![]()
приводит к новому качеству.
Таким образом, нейроалгоритмы представляют собой удобный инструмент нелинейного анализа, позволяющий относительно легко находить способы глубокого сжатия информации и выделения нетривиальных признаков.
5.4 Выводы по разделу.
Конечно, описанными выше методиками не исчерпывается все разнообразие подходов к ключевой для нейро-анализа проблеме формирования пространства признаков. Например, существуют различные методики, расширяющие анализ главных компонент. Также, большего внимания заслуживают генетические алгоритмы. Необъятного не объять. Главное, чтобы за деталями не терялся основополагающий принцип предобработки данных: снижение существующей избыточности всеми возможными способами. Это повышает информативность примеров и, тем самым, качество нейропредсказаний.
6. Реализация нейросетевой модели и исследование ее технических характеристик.
Ранее было показано, какими средствами нейроинформатики можно пытаться решить задачу идентификации типа сейсмического источника, какие процедуры целесообразно применять при предварительной подготовке данных, был приведен небольшой обзор различных алгоритмов обучения известных нейроархитектур. В этой главе представлено решение задачи на базе двухслойного персептрона, так как именно он был выбран на начальном этапе исследований. Дано также описание алгоритма обучения и методов его оптимизации.
6.1 Структура нейронной сети.
Итак, для решения задачи идентификации типа сейсмического события предлагается использовать одну из самых универсальных нейроархитектур – многослойный персептрон, а точнее его двухслойную реализацию (рис. 6.1). Как показали эксперименты, увеличение числа скрытых слоев не приводит к лучшим результатам, а лишь усложняет процесс обучения, поэтому и была выбрана именно реализация с одним скрытым слоем нейронов.
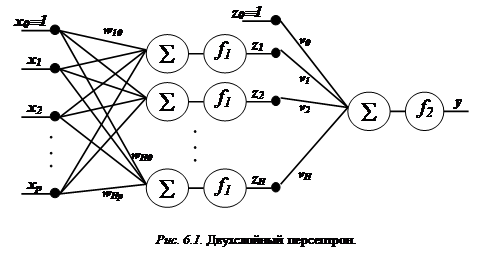
На вход сети подается p-мерный вектор признаков {xi, i=1,2,…,p}. Для определенности будем рассматривать случай, когда p=9, хотя исследования проводились и для p=5, p=18. Оптимальное количество нейронов на скрытом слое H подбиралось экспериментально для разных p. Соответственно при p = 9 достаточно брать H равным также 9 или немного больше. Для разбиения исходных данных на два класса на выходе сети достаточно одного нейрона. Между входным и скрытым слоями, а также между скрытым и выходным слоями использовалась полносвязная структура.
С учетом этих дополнений опишем принятые на рисунке 7.1 обозначения:
p – размерность исходных данных (количество признаков используемых для классификации);
H – число нейронов на скрытом слое;
xi – компонента входного вектора признаков, i = 1,…,p;
x0 º 1 – постоянное воздействие используемое для работы нейронной сети;
wji – весовые коэффициенты между входным и скрытым слоями, i = 0,1,…,p , j = 1,…,H;
vk - весовые коэффициенты между скрытым и выходным слоями, k = 0,1,…,H.
zj – значение выхода j-го нейрона скрытого слоя; z0 º 1, j = 1,…,H;
![]()
y – значение выходного нейрона сети (выход сети)
![]() (12)
(12)
f1(x) –функция активации нейронов скрытого слоя;
f2(x) –функция активации нейрона выходного слоя.
В качестве функции активации f1(x) для нейронов скрытого слоя и f2(x) для единственного нейрона на выходе сети предлагается использовать одну и ту же функцию, а именно сигмоидную функцию активации, для краткости будем обозначать ее как f(x):
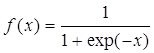 ,
,
с производной в виде
![]() .
.
Вид такой функции представлен на рис.6.2
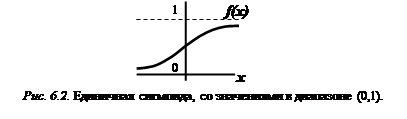
Т.к. значения функции f(x) ограничены в диапазоне [0, 1], результат сети y(x) может принимать любые действительные значения из этого же диапазона, в следствии чего логично интерпретировать выходы сети следующим образом: если y(x) > 0.5, то вектор принадлежит к одному классу (взрывы), в противном случае к другому (землетрясения).
6.2 Исходные данные.
На вход нейронной сети предлагается подавать вектора признаков составленные из сейсмограмм. О том, какие признаки были использованы для этой задачи и как они получены, было рассказано ранее в разделе 3.1. Стоит отметить, что проблема формирования векторов признаков – это исключительно проблема сейсмологии. Поэтому для исследования эффективности применения нейронных сетей в качестве исходных данных были использованы уже готовые выборки векторов, которые содержали в себе примеры и землетрясений и взрывов.
Размерность векторов признаков p=9, хотя , как было отмечено в предыдущем разделе, проводились эксперименты и с другим количеством признаков.
Для работы с нейросетью рекомендуется использовать исходные данные не в первоначальном виде, а после предварительной обработки при помощи процедуры индивидуальной нормировки по отдельному признаку, описанной в разделе 5.2. Это преобразование состоит в следующем:
![]()
где
xi – исходное значение вектора признаков, точнее его i-я компонента;
xi,min – минимальное значение по i-му признаку, найденное из всей совокупности исходных данных, включающей оба класса событий;
xi,max – максимальное значение по i-му признаку …
Выбор именно этой нормировки, а не более универсальных, которые описаны в разделе 5, в настоящих исследованиях продиктованы тем обстоятельством, что непосредственно признаки измеренные по сейсмограммам, подвергаются последовательно двум нелинейным преобразованиям в соответствии с функциями
y=Ln(x) и z=(1/7)(y1/7-1),
и уже из этих значений формируются обучающие вектора. Такие преобразования приводят к большей кластеризации точек в многомерном пространстве, однако диапазон изменения каждого из признаков не нормирован относительно интервала [-1, 1], а выбранная нормировка позволяет без потери информации перенести все входные значения в нужный диапазон.
6.3 Определение критерия качества системы и функционала его оптимизации.
Если
через ![]() обозначить желаемый выход
сети (указание учителя), то ошибка системы для заданного входного сигнала
(рассогласование реального и желаемого выходного сигнала) можно записать в
следующем виде:
обозначить желаемый выход
сети (указание учителя), то ошибка системы для заданного входного сигнала
(рассогласование реального и желаемого выходного сигнала) можно записать в
следующем виде:
![]()
![]() , где
, где
k — номер обучающей пары в обучающей выборке, k=1,2,…,n1+n2
n1 - количество векторов первого класса;
n2 - число векторов второго класса.
В качестве функционала оптимизации будем использовать критерий минимума среднеквадратической функции ошибки:
![]()
6.4 Выбор начальных весовых коэффициентов.
Перед тем, как приступить к обучению нейронной сети, необходимо задать ее начальное состояние. От того насколько удачно будут выбраны начальные значения весовых коэффициентов зависит, как долго сеть за счет обучения и подстройки будет искать их оптимальное величины и найдет ли она их.
Как правило, всем весам на этом этапе присваиваются случайные величины равномерно распределенные в диапазоне [-A,A], например [-1,1], или [-3,3]. Однако, как показали эксперименты, данное решение не является наилучшим и в качестве альтернативы предлагается использовать другие виды начальной инициализации, а именно:
1. Присваивать весам случайные величины, заданные не равномерным распределением, а нормальным распределением с параметрами N[a,s], где выборочное среднее a=0, а дисперсия s = 2, или любой другой небольшой положительной величине. Для формирования нормально распределенной величины можно использовать следующий алгоритм:
Шаг 1. Задать 12 случайных чисел x1, x2, …,x12 равномерно распределенных в диапазоне [0,1]. xi Í R[0,1].
Шаг 2. Для
искомых параметров a и s величина ![]() ,
полученная по формуле:
,
полученная по формуле:
![]()
будет принадлежать нормальному распределению с параметрами N[a,s].
2. Можно производить начальную инициализацию весов в соответствии с методикой, предложенной Nguyen и Widrow [7]. Для этой методики используются следующие переменные
![]() число нейронов текущего слоя
число нейронов текущего слоя
![]() количество нейронов последующего слоя
количество нейронов последующего слоя
![]() коэффициент масштабирования:
коэффициент масштабирования:
![]()
Вся процедура состоит из следующих шагов:
Для каждого нейрона последующего слоя![]() :
:
Инициализируются весовые коэффициенты (с нейронов текущего слоя):
![]() случайное число в диапазоне [-1,1] ( или
случайное число в диапазоне [-1,1] ( или ![]() ).
).
Вычисляется норма ![]()
Далее веса преобразуются в соответствии с правилом:
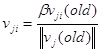
Смещения ![]() выбираются
случайным образом из диапазона
выбираются
случайным образом из диапазона ![]() .
.
Обе предложенные методики позволили на практике добиться лучших результатов, в сравнении со стандартным алгоритмом начальной инициализации весов.
6.5 Алгоритм обучения и методы его оптимизации.
Приступая к обучению выбранной нейросетевой модели, необходимо было решить, какой из известных типов алгоритмов, градиентный (обратное распространения ошибки) или стохастический (Больцмановское обучение) использовать. В силу ряда субъективных причин был выбран именно первый подход, который и представлен в этом разделе.
Обучение нейронных сетей как минимизация функции ошибки.
Когда функционал ошибки нейронной сети задан (раздел 6.3), то главная задача обучения нейронных сетей сводится к его минимизации. Градиентное обучение – это итерационная процедура подбора весов, в которой каждый следующий шаг направлен в сторону антиградиента функции ошибки. Математически это можно выразить следующим образом:
![]() , или , что то же самое :
, или , что то же самое : ![]() ,
,
здесь ht - темп обучения на шаге t. В теории оптимизации этот метод известен как метод наискорейшего спуска.[]
Метод обратного распространения ошибки.
Исторически наибольшую
трудность на пути к эффективному правилу обучения многослойных персептронов
вызвала процедура расчета градиента функции ошибки ![]() .
Дело в том, что ошибка сети определяется по ее выходам, т.е. непосредственно
связана лишь с выходным слоем весов. Вопрос состоял в .том, как определить
ошибку для нейронов на скрытых слоях, чтобы найти производные по соответствующим
весам. Нужна была процедура передачи ошибки с выходного слоя к предшествующим
слоям сети, в направлении обратном обработке входной информации. Поэтому такой
метод, когда он был найден, получил название метода обратного
распространения ошибки (error back-propagation ).
.
Дело в том, что ошибка сети определяется по ее выходам, т.е. непосредственно
связана лишь с выходным слоем весов. Вопрос состоял в .том, как определить
ошибку для нейронов на скрытых слоях, чтобы найти производные по соответствующим
весам. Нужна была процедура передачи ошибки с выходного слоя к предшествующим
слоям сети, в направлении обратном обработке входной информации. Поэтому такой
метод, когда он был найден, получил название метода обратного
распространения ошибки (error back-propagation ).
Разберем этот метод на примере двухслойного персептрона с одним нейроном на выходе.(рис 6.1) Для этого воспользуемся введенными ранее обозначениями. Итак,
![]() -Функция ошибки (13)
-Функция ошибки (13)
![]() -необходимая коррекция весов
коррекция весов (14)
-необходимая коррекция весов
коррекция весов (14)
для выходного слоя Dv записывается следующим образом.
![]()
Коррекция весов между входным и скрытым слоями производится по формуле:
![]() (15)
(15)
![]()
![]()
![]()
Подставляя одно выражение в другое получаем
![]() (16)
(16)
Производная функции активации, как
было показано ранее (раздел 6.1), вычисляется через значение самой функции. ![]()
![]()
Непосредственно алгоритм обучения состоит из следующих шагов:
1. Выбрать очередной вектор из обучающего множества и подать его на вход сети.
2. Вычислить выход сети y(x) по формуле (12).
3. Вычислить разность между выходом сети и требуемым значением для данного вектора (13).
4. Если была допущена ошибка при классификации выбранного вектора, то подкорректировать последовательно веса сети сначала между выходным и скрытым слоями (15), затем между скрытым и входным (16).
5. Повторять шаги с 1 по 4 для каждого вектора обучающего множества до тех пор, пока ошибка на всем множестве не достигнет приемлемого уровня.
Страницы: 1, 2, 3, 4, 5, 6, 7, 8
