

 Реферат: Классификация сейсмических сигналов на основе нейросетевых технологий
Реферат: Классификация сейсмических сигналов на основе нейросетевых технологий
Основным недостатком этой группы алгоритмов является очень долгое время обучения, а соответственно и большие вычислительные затраты. Однако, как пишут в различных источниках, эти алгоритмы обеспечивают глобальную оптимизацию, в то время как градиентные методы в большинстве случаев позволяют найти только локальные минимумы функционала ошибки.
Известны также алгоритмы, которые основаны на совместном использовании обратного распространения и обучения Коши. Коррекция весов в таком комбинированном алгоритме состоит из двух компонент: направленной компоненты, вычисляемой с использованием алгоритма обратного распространения, и случайной компоненты, определяемой распределением Коши. Однако, несмотря на хорошие результаты, эти методы еще плохо исследованы.
4.3 Сети Ворда.
Одним из вариантов многослойного персептрона являются нейронные сети Ворда. Они способны выделять различные свойства в данных, благодаря наличию в скрытом слое нескольких блоков, каждый из которых имеет свою передаточную функцию (рис.4.4). Передаточные функции (обычно сигмоидного типа) служат для преобразования внутренней активности нейрона. Когда в разных блоках скрытого слоя используются разные передаточные функции, нейросеть оказывается способной выявлять новые свойства в предъявляемом образе. Для настройки весовых коэффициентов используются те же алгоритмы, о которых говорилось в предыдущем разделе.
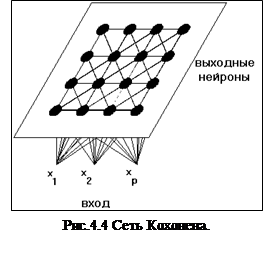
4.2 Сети Кохонена.
Сети Кохонена – это одна из разновидностей нейронных сетей, для настройки которой используется алгоритм обучения без учителя. Задачей нейросети Кохонена является построение отображения набора входных векторов высокой размерности на карту кластеров меньшей размерности , причем таким образом, что близким кластерам на карте отвечают близкие друг к другу входные векторы в исходном пространстве.
Сеть состоит из M нейронов, образующих, как правило одномерную или двумерную карту (рис. 4.2). Элементы входных сигналов {xi} подаются на входы всех нейронов сети. В процессе функционирования (самоорганизации) на выходе слоя Кохонена формируются кластеры (группа активных нейронов определённой размерности, выход которых отличен от нуля), характеризующие определённые категории входных векторов (группы входных векторов, соответствующие одной входной ситуации). [9]
Алгоритм Кохонена формирования карт признаков.
Шаг 1. Инициализировать веса случайными значениями. Задать размер окрестности s(0), и скорость h(0) и tmax.
Шаг 2. Задать значения входных сигналов (x1,…,xp).
Шаг 3. Вычислить расстояние до всех нейронов сети. Расстояния dk от входного сигнала x до каждого нейрона k определяется по формуле:
![]()
где
xi - i-ый элемент входного сигнала,
wki - вес связи от i-го элемента входного сигнала к нейрону k.
Шаг 4. Найти нейрон – победитель, т.е. найти нейрон j, для которого расстояние dj наименьшее:
j:dj < dk "k¹p
Шаг 5. Подстроить веса победителей и его соседей.
![]()
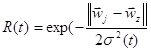
Шаг 6. Обновить размер окрестности s(t) и скорость h(t)
s(t)=s(0)(1-t/tmax) h(t)=h(0)(1-t/tmax)
Шаг 7. Если (t < tmax), то Шаг 2, иначе СТОП.
Благодаря своим способностям к обобщению информации, карты Кохонена являются удобным инструментом для наглядного представления о структуре данных в многомерном входном пространстве, геометрию которого представить практически невозможно.
Сети встречного распространения.
Еще одна группа технических применений связана с предобработкой данных. Карта Кохонена группирует близкие входные сигналы Х, а требуемая функция Y = G(X) строится на основе обычной нейросети прямого распространения (например многослойного персептрона или линейной звезды Гроссберга[1]) к выходам нейронов Кохонена. Такая гибридная архитектура была предложена Р. Хехт-Нильсеном и имеет название сети встречного распространения[1-3,7,9]. Нейроны слоя Кохонена обучаются без учителя, на основе самоорганизации, а нейроны распознающих слоев адаптируются с учителем итерационными методами. Пример такой структуры для решения задачи классификации сейсмических сигналов приведен на рис. 4.5.
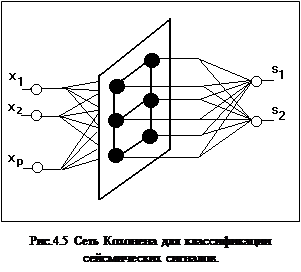
Второй уровень нейросети используется для кодирования информации. Весовые коэффициенты tij (i =1,...,M; j=1,2) – коэффициенты от i-го нейрона слоя Кохонена к j-му нейрону выходного слоя рассчитываются следующим образом:
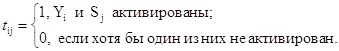
где
Yi – выход i- го нейрона слоя Кохонена
Sj – компонента целевого вектора (S={0,1} – взрыв, S={1,0}-землетрясение)
Таким образом после предварительного обучения и формирования кластеров в слое Кохонена, на фазе вторичного обучения все нейроны каждого полученного кластера соединяются активными (единичными) синапсами со своим выходным нейроном, характеризующим данный кластер.
Выход нейронов второго слоя определяется выражением:
(11) 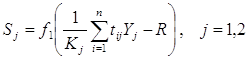
где: ![]()
Kj - размерность j-ого кластера, т.е. количество нейронов слоя Кохонена соединённых с нейроном j выходного слоя отличными от нуля коэффициентами.
R - пороговое значение (0 < R < 1).
Пороговое значение R можно выбрать таким образом, чтобы с одной стороны не были потеряны значения активированных кластеров, а с другой стороны - отсекался "шум не активизированных кластеров".
В результате на каждом
шаге обработки исходных данных на выходе получаются значения Sj,
которые характеризуют явление, породившее данную входную ситуацию (![]() - землетрясение;
- землетрясение; ![]() - взрыв).
- взрыв).
4.5 Выводы по разделу.
Итак, подводя итог данной главе, следует сказать, что это далеко не полный обзор нейросетевых архитектур, которые успешно справляются с задачами классификации. В частности ничего не было сказано о вероятностных нейронных сетях, о сетях с базисно радиальными функциями, о использовании генетических алгоритмов для настройки многослойных сетей и о других, пусть менее известных, но хорошо себя зарекомендовавших. Соответственно проблема выбора наиболее оптимальной архитектуры для решения задачи классификации сейсмических сигналов вполне актуальна. В идеале, конечно хотелось бы проверить эффективность хотя бы нескольких из них и выбрать наилучшую. Но для этого необходимо проводить более масштабные исследования, которые займут много времени. На данном этапе исследований была сделана попытка использовать хорошо изученные нейронные сети и алгоритмы обучения для того, чтобы убедиться в эффективности подхода в целом. В главе 6 детально обсуждаются нейросеть, которая была исследована в рамках настоящей дипломной работы.
5. Методы предварительной обработки данных.
Если возникает необходимость использовать нейросетевые методы для решения конкретных задач, то первое с чем приходится сталкиваться – это подготовка данных. Как правило, при описании различных нейроархитектур, по умолчанию предполагают что данные для обучения уже имеются и представлены в виде, доступном для нейросети. На практике же именно этап предобработки может стать наиболее трудоемким элементом нейросетевого анализа. Успех обучения нейросети также может решающим образом зависеть от того, в каком виде представлена информация для ее обучения.
В этой главе рассматриваются различные процедуры нормировки и методы понижения размерности исходных данных, позволяющие увеличить информативность обучающей выборки.
5.1 Максимизация энтропии как цель предобработки.
Рассмотрим основной руководящий принцип, общий для всех этапов предобработки данных. Допустим, что в исходные данные представлены в числовой форме и после соответствующей нормировки все входные и выходные переменные отображаются в единичном кубе. Задача нейросетевого моделирования – найти статистически достоверные зависимости между входными и выходными переменными. Единственным источником информации для статистического моделирования являются примеры из обучающей выборки. Чем больше бит информации принесет пример – тем лучше используются имеющиеся в нашем распоряжении данные.
Рассмотрим произвольную компоненту нормированных
(предобработанных) данных: ![]() . Среднее
количество информации, приносимой каждым примером
. Среднее
количество информации, приносимой каждым примером ![]() ,
равно энтропии распределения значений этой компоненты
,
равно энтропии распределения значений этой компоненты ![]() . Если эти значения
сосредоточены в относительно небольшой области единичного интервала,
информационное содержание такой компоненты мало. В пределе нулевой энтропии, когда
все значения переменной совпадают, эта переменная не несет никакой информации.
Напротив, если значения переменной
. Если эти значения
сосредоточены в относительно небольшой области единичного интервала,
информационное содержание такой компоненты мало. В пределе нулевой энтропии, когда
все значения переменной совпадают, эта переменная не несет никакой информации.
Напротив, если значения переменной ![]() равномерно
распределены в единичном интервале, информация такой переменной максимальна.
равномерно
распределены в единичном интервале, информация такой переменной максимальна.
Общий принцип предобработки данных для обучения, таким образом состоит в максимизации энтропии входов и выходов.
5.2 Нормировка данных.
Как входами, так и выходами могут быть совершенно разнородные величины. Очевидно, что результаты нейросетевого моделирования не должны зависеть от единиц измерения этих величин. А именно, чтобы сеть трактовала их значения единообразно, все входные и выходные величин должны быть приведены к единому масштабу. Кроме того, для повышения скорости и качества обучения полезно провести дополнительную предобработку, выравнивающую распределения значений еще до этапа обучения.
Индивидуальная нормировка данных.
Приведение к единому масштабу обеспечивается нормировкой каждой переменной на диапазон разброса ее значений. В простейшем варианте это – линейное преобразование:
![]()
в единичный отрезок: ![]() . Обобщение для отображения
данных в интервал
. Обобщение для отображения
данных в интервал ![]() , рекомендуемого
для входных данных тривиально.
, рекомендуемого
для входных данных тривиально.
Линейная нормировка
оптимальна, когда значения переменной ![]() плотно
заполняют определенный интервал. Но подобный «прямолинейный» подход применим
далеко не всегда. Так, если в данных имеются относительно редкие выбросы,
намного превышающие типичный разброс, именно эти выбросы определят согласно
предыдущей формуле масштаб нормировки. Это приведет к тому, что основная масса
значений нормированной переменной
плотно
заполняют определенный интервал. Но подобный «прямолинейный» подход применим
далеко не всегда. Так, если в данных имеются относительно редкие выбросы,
намного превышающие типичный разброс, именно эти выбросы определят согласно
предыдущей формуле масштаб нормировки. Это приведет к тому, что основная масса
значений нормированной переменной ![]() сосредоточится
вблизи нуля
сосредоточится
вблизи нуля ![]() Гораздо надежнее, поэтому,
ориентироваться при нормировке не а экстремальные значения, а на типичные, т.е.
статистические характеристики данных, такие как среднее и дисперсия.
Гораздо надежнее, поэтому,
ориентироваться при нормировке не а экстремальные значения, а на типичные, т.е.
статистические характеристики данных, такие как среднее и дисперсия.
![]() , где
, где
![]() ,
, ![]()
В этом случае основная масса данных будет иметь единичный масштаб, т.е. типичные значения все переменных будут сравнимы (рис. 6.1)
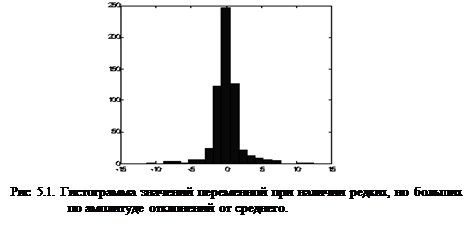
Однако, теперь нормированные величины не принадлежат
гарантированно единичному интервалу, более того, максимальный разброс значений ![]() заранее не известен. Для
входных данных это может быть и не важно, но выходные переменные будут
использоваться в качестве эталонов для выходных нейронов. В случае, если
выходные нейроны – сигмоидные, они могут принимать значения лишь в единичном
диапазоне. Чтобы установить соответствие между обучающей выборкой и нейросетью
в этом случае необходимо ограничить диапазон изменения переменных.
заранее не известен. Для
входных данных это может быть и не важно, но выходные переменные будут
использоваться в качестве эталонов для выходных нейронов. В случае, если
выходные нейроны – сигмоидные, они могут принимать значения лишь в единичном
диапазоне. Чтобы установить соответствие между обучающей выборкой и нейросетью
в этом случае необходимо ограничить диапазон изменения переменных.
Линейное преобразование, представленное выше, не способно отнормировать основную массу данных и одновременно ограничить диапазон возможных значений этих данных. Естественный выход из этой ситуации – использовать для предобработки данных функцию активации тех же нейронов. Например, нелинейное преобразование
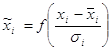 ,
, ![]()
нормирует основную массу данных одновременно гарантируя что![]() (рис. 5.2)
(рис. 5.2)
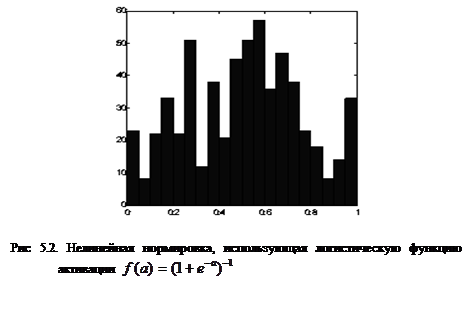
Как видно из приведенного выше рисунка, распределение значений после такого нелинейного преобразования гораздо ближе к равномерному.
Все выше перечисленные методы нормировки направлены на то, чтобы максимизировать энтропию каждого входа (выхода) по отдельности. Но, вообще говоря, можно добиться гораздо большего максимизируя их совместную энтропию. Существуют методы, позволяющие проводить нормировку для всей совокупности входов, описание некоторых из них приведено в [4].
6.3 Понижение размерности входов.
Поскольку заранее неизвестно насколько полезны те или иные входные переменные для предсказания значений выходов, возникает соблазн увеличивать число входных параметров, в надежде на то, что сеть сама определит, какие из них наиболее значимы. Однако чаще всего это не приводит к ожидаемым результатам, а к тому же еще и увеличивает сложность обучения. Напротив, сжатие данных, уменьшение степени их избыточности, использующее существующие в них закономерности, может существенно облегчить последующую работу, выделяя действительно независимые признаки. Можно выделить два типа алгоритмов, предназначенных для понижения размерности данных с минимальной потерей информации:
· Отбор наиболее информативных признаков и использование их в процессе обучения нейронной сети;
· Кодирование исходных данных меньшим числом переменных, но при этом содержащих по возможности всю информацию, заложенную в исходных данных.
Рассмотрим более подробно оба типа алгоритмов.
5.3.1 Отбор наиболее информативных признаков.
Для того, чтобы понять какие из входных переменных несут максимум информации, а какими можно пренебречь необходимо либо сравнить все признаки между собой и определить степень информативности каждого из них, либо пытаться найти определенные комбинации признаков, которые наиболее полно отражают основные характеристики исходных данных.
В разделе 3.2 был описан алгоритм, позволяющий упорядочить все признаки по мере убывания их значимости. Однако накладываемые ограничения не позволяют применять его для более распространенных задач.
Для выбора подходящей комбинации входных переменных используется так называемые генетические алгоритмы [5], которые хорошо приспособлены для задач такого типа, поскольку позволяют производить поиск среди большого числа комбинаций при наличии внутренних зависимостей в переменных.
5.3.2 Сжатие информации. Анализ главных компонент.
Самый распространенный метод понижения размерности - это анализ главных компонент (АГК).
Традиционная реализация этого метода представлена в теории линейной алгебры. Основная идея заключается в следующем: к данным применяется линейное преобразование, при котором направлениям новых координатных осей соответствуют направления наибольшего разброса исходных данных. Для эти целей определяются попарно ортогональные направления максимальной вариации исходных данных, после чего данные проектируются на пространство меньшей размерности, порожденное компонентами с наибольшей вариацией [4]. Один из недостатков классического метода главных компонент состоит в том, что это чисто линейный метод, и соответственно он может не учитывать некоторые важные характеристики структуры данных.
В теории нейронных сетей разработаны более мощные алгоритмы, осуществляющие “нелинейный анализ главных компонент”[3]. Они представляют собой самостоятельную нейросетевую структуру, которую обучают выдавать в качестве выходов свои собственные входные данные, но при этом в ее промежуточном слое содержится меньше нейронов, чем во входном и выходном слоях. (рис 5.3). Сети подобного рода носят название – автоассоциативные сети.
Страницы: 1, 2, 3, 4, 5, 6, 7, 8
