

 Реферат: Бакалаврская работа. Программная модель 32-разядной МЭВМ фирмы Motorola
Реферат: Бакалаврская работа. Программная модель 32-разядной МЭВМ фирмы Motorola
Команда MOVEA (move address) предназначена для инициализации адресного регистра. Только слово и длинное слово, как операнды, возможно перемещать непосредственно в адресный регистр. Для операции со словом, операнд-источник перед помещением в регистр адреса переводится в 32-х разрядную сетку с учётом знака.
Команда MOVEQ (move quick) - это укороченная форма команды перемещения непосредственного операнда в регистр данных. Непосредственный операнд ограничен диапазоном от -128 до 127. Под размерностью операции подразумевается длинное слово. Следовательно, 8-битный непосредственный операнд должен быть преобразован в 32-битовый знаковый перед перемещением его в приёмник, которым является регистр данных. Некоторые ассемблеры могут различать три формы: MOVE data, MOVEA и MOVEQ по операндам, т.к. каждая форма определяется своим единственным типом операнда. Для таких ассемблеров некоторые мнемоники команды MOVE могут быть использованы также успешно для MOVEA и MOVEQ, т. к. соответствующие коды операции ассемблируются согласно операнду.
Для иллюстрации работы команды MOVE, присвоим D1=56789ABC, A1=01020304 и CCR=0010001 установим перед выполнением команды. После того, как показанные ниже команды будут выполнены, мы получим следующие результаты:
MOVE #0,CCR На регистр или память нет воздействия,
N=0, Z=0, V=0, C=0, X=0
MOVE.W A1,D1 D1=56780304,
N=0, Z=0, V=0, C=0, X=1
MOVE D1,A1 A1=FFFF9ABC,
N=0, Z=0, V=0, C=1, X=1
MOVE #-10,D1 D1=FFFFFFF6,
N=1, Z=0, V=0, C=0, X=1
Команды MOVEM и MOVEP
Команда MOVEM (move multiple register) переносит слово или длинное слово между списком регистров и последовательно идущими участками памяти. В случае, когда слово перемещают в регистр, каждое слово памяти должно быть преобразовано в 32-х разрядную сетку с учётом знака перед загрузкой в соответствующий регистр. Каждый регистр, участвующий в перемещении, может быть указан в списке и отделён символом "/", возможно также указание в списке начального и конечного регистра, разделенных символом "-". В памяти выделенные регистры всегда располагаются так, что D0 переписывается по младшему адресу, D1 в следующий, ... , затем с A0 по A7, причем A7 записывается в самый верхний адрес памяти. При перемещении регистров в память адрес операнда памяти может определяться в зависимости от управляющего способа адресации или режимом с предекрементом. Для обратного перемещения эффективный адрес может быть определён в зависимости от управляющего способа адресации или режимом с постинкрементом.
Типовое применение команды MOVEM - это запись и восстановление регистров в стек при обращении к подпрограммам. Перед вызовом подпрограммы все регистры могут быть записаны в стек системы посредством выполнения команды
MOVEM.L D0-D7/A0-A6,-(A7)
При возврате в управляющую программу, эти регистры восстанавливаются к своему первоначальному виду командой
MOVEM.L (A7)+,D0-D7/A0-A6
Заметьте, что хотя команда MOVEM.L (A7),D0-D7/A0-A6 будет также восстанавливать содержимое записанных регистров, но указатель стека A7 при этом не будет обновлён с присвоением значения, которое было изначально в вершине стека.
Команда MOVEP (move peripherial data) предназначена для облегчения программного ввода/вывода. Множество интерфейсов ввода/вывода - 8-битные устройства. Для простоты связи между 16-битной адресной шиной и 8-битным устройством ввода/вывода, устройство соединяется с каждым младшим или старшим байтом шины данных. В случае соединения с младшим байтом, все внутренние регистры устройства доступны через последовательность нечётных адресов. В другой конфигурации все внутренние регистры доступны через последовательность чётных адресов. Команда MOVEP может осуществлять ввод/вывод данных из (в) двух (для операции со словом) или четырёх (для операции с длинным словом) последовательно расположенных регистров устройства ввода/вывода. Только косвенный регистровый способ адресации со смещением допускается для определения порта ввода/вывода. На Рис. 14 показаны два примера работы команды MOVEP.
Команды EXG и SWAP
Команда EXG (exchange) осуществляет обмен содержимого двух регистров, в то время как команда SWAP обменивает младшее слово в регистре данных со старшим словом. Подразумевается, что размерность операнда для EXG - длинное слово, для SWAP - слово.
Команды LEA и PEA
Команда LEA (load effective address) перемещает адрес операнда-источника (а не его содержимое) в адресный регистр - приёмник. Следовательно, команда
MOVEA.L #OPER,A1
эквивалентна команде
LEA OPER,A1
Команда PEA (push effective address) записывает адрес операнда-источника в стек системы. Эта команда обычно используется для передачи адресов параметра в подпрограмму через стек. Операндами-источниками для обеих команд LEA и PEA должны быть операнды памяти.
В качестве некоторой иллюстрации к описанным командам, предположим, что мы хотим записать несложную последовательность команд, которая будет перемещать 4 длинных слова из массива ABC в начало массива XYZ. Простая последовательность, выполняющая это, следующая:
MOVE.L ABC,XYZ
MOVE.L ABC+4,XYZ+4
MOVE.L ABC+8,XYZ+8
MOVE.L ABC+12,XYZ+12
Те же действия могут быть выполнены двумя командами:
MOVEM ABC,D0-D3
MOVEM D0-D3,XYZ
Ещё один способ иллюстрируется следующей последовательностью команд:
MOVEA.L #ABC,A1
MOVEA.L #XYZ,A2
MOVE.L (A1)+,(A2)+
MOVE.L (A1)+,(A2)+
MOVE.L (A1)+,(A2)+
MOVE.L (A1)+,(A2)+
В этом способе, использующем постинкрементный способ адресации, одна и та же команда MOVE.L повторяется для перемещения последующих элементов. Следовательно, эта последовательность команд может быть легче преобразована в итерационный цикл для перемещения большого числа элементов между двумя массивами.
Результатом проектирования является программная модель, наиболее точно реализующая все вышеперечисленные особенности микропроцессора MC 68300. Особое внимание уделено способам адресации, в частности программная модель реализует 14 способов адресации предусмотренных в микропроцессоре, возможности ввода данных в различных системах счисления, в частности в системах по основанию 2, 10, 16. Общую структуру программы для наглядности можно представить на рисунке 2:

Ввод
данных
Рисунок 2 – Общая структура программы.
Модуль интерпретатора реализует следующие функции:
- проверку на наличие ошибок в синтаксисе команд, введённых пользователем,
- приведение всех операндов к системе счисления с основанием 16,
- возможность просмотра эффективного адреса операндов (ЕА);
- приведение всех команд к форме, понятной обработчику.
Модуль обработки команд, по желанию пользователя может осуществлять как выполнение всей программы, так и её пошаговую трассировку и осуществляет выполнение команд в соответствии с их мнемокодом.
После обработки команд, у пользователя есть возможность просмотра результата их выполнения, т.е. активным становится модуль интерфейса.
5. Интерфейс, органы управления
После запуска программы пользователь получает доступ к графическому интерфейсу, позволяющему осуществлять ввод, корректировку и вывод данных в диалоговом режиме (рис.1).
Программная модель поддерживает два режима работы: супервизора и пользователя, каждый из которых характеризуется своим множеством операций. После запуска программы появляется окно, позволяющее пользователю выбрать режим работы. В пользовательском режиме процессор работает с определёнными ограничениями. Хотя большинство команд микропроцессора выполняется одинаково в обоих режимах, некоторые команды, вызывающие особые действия в системе, в пользовательском режиме запрещены.
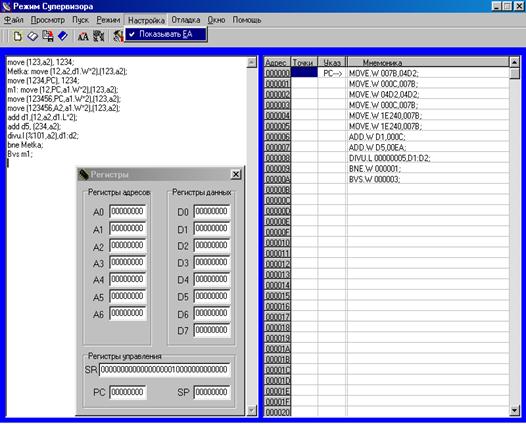
Рис. 3
Основной экран программы состоит из двух окон: окно для ввода текста программы (диалоговое окно) и окно отладчика, в котором отражается адрес команды в памяти, положение указателя стека, мнемоника команды и её машинный код. Программная модель обладает возможностью просмотра и корректировки промежуточных результатов выполнения микропроцессорных программ. Для этой цели в неё включены возможности просмотра содержимого регистров микропроцессора. Осуществляется это путём выбора соответствующего подменю в выпадающем меню PopUp (Просмотр/Регистры). Микропроцессор имеет 17 32-разрядных регистров (восемь регистров данных, семь адресных регистров и два указателя стека). Кроме того, в нём есть 32-разрядный счётик команд, в котором используются только младшие 24 разряда. Регистр состояния микропроцессора имеет 16 разрядов. Все эти регистры отображены в соответствующем окне (рис. 2). Закрыть окна просмотра регистров можно щёлкнув на системную иконку закрытия окна или же выбрав в меню пункт “Окно”, ”Закрыть все”
Переключение между режимами осуществляется путём выбора соответствующего режима в меню “Режим”. При переключении между режимами все данные, введённые пользователем должны быть сохранены, о чём появится соответствующая подсказка.
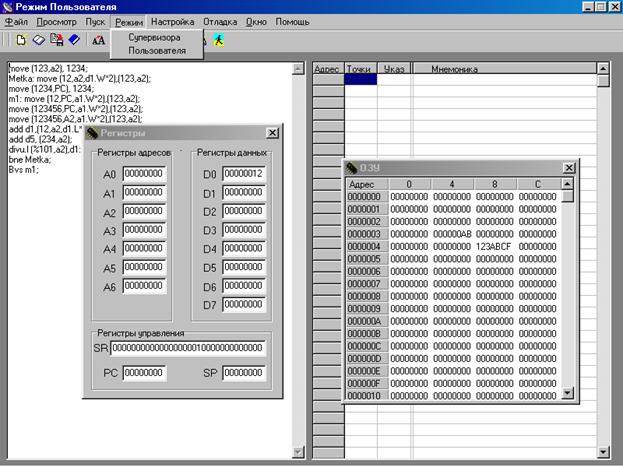
Рис. 4
Программная модель предоставляет пользователю возможность работы с файлами. Для этой цели в меню “Файл” необходимо выбрать нужное действие (Создание нового программного листа, открытие уже существующего, сохранение редактируемого, его закрытие). Здесь также существует возможность выхода из программы, все в дальнейшем необходимые данные должны быть предварительно сохранены.
В меню “Пуск” отражены команды, управляющие выполнением и отладкой микропроцессорных программ. Команда “Выполнить” выполняет программу из диалогового окна. Команда “Останов” прерывает выполнение программы. Команда “Ассемблирование” переводит мнемонику команд в ассемблерный код, который также отображается в соответствующем окне. Команда “Дизассемблирование” наоборот переводит машинный код в мнемонику, понятную пользователю. Команда “Трассировка” позволяет выполнять программу в пошаговом режиме, что может быть полезно для уяснения тонкостей алгоритма выполнения программы, а также может использоваться для устранения ошибок в программном коде.
В меню также существует пункт “Помощь”, где пользователь сможет найти всю интересующую его информацию по работе программной модели, устройству микропроцессора и его системе команд.
Для облегчения работы, наиболее часто выполняемые операции вынесены на панель инструментов.
6. Применение программной модели.
Программная модель дает широкие и удобные возможности для набора и отладки учебных программ (к примеру, может быть возможен одновременный просмотр всех регистров, памяти, ввод команд в мнемонических обозначениях, ассемблирование команд и т. д.).
Применение программной модели дает значительную экономию времени и сил, за счет более удобной отладки и набора программы. Посредством разработанной программы студентам предоставляется возможность изучить различные способы адресации, систему команд и устройство MC 68300.
Примером программы, предложенной для обучения, может служить программа вычисления максимального элемента массива значений, размером в слово (WORD).
move #10,D0 ; задаёт размерность массива 10->DO
M1: move (a1),d1 ; загружает содержимое ячейки памяти по адр. А1->D1
movea d3,A2 ; загружает содержимое регистра D3->A2
move d1,d3 ; D3->D1
sub A2,D1 ;D1-A2->D1
SPL Met ; если положительный результат, то переход на Met:
move a2,d3 ; A2-D3
Met: adda #2,a1 ; A1+2->A1
sub #1,D0 ;D0-1->D0
sne M1 ; если ненулевой результат, то переход на M1
move d3,d0 ; D3->D0.
Посредством наглядного интерфейса пользователь может просмотреть покомандно выполнение программы (так называемый режим трассировки), содержимое регистров и флагов и их изменение при выполнении команд. Существует также возможность быстрого выполнения команды, что обеспечивает возможность почти мгновенного получения результатов обработки.
7. Описание интерпретатора
При разработке программной модели этап лексической обработки текста исходной программы выделяется в отдельный этап работы компилятора, как с методическими целями, так и с целью сокращения общего времени компиляции программы. Последнее достигается за счет того, что исходная программа, представленная на входе компилятора в виде непрерывной последовательности символов, на этапе лексической обработки преобразуется к некоторому стандартному виду, что облегчает дальнейший анализ. При этом используются специализированные алгоритмы преобразования, теория и практика построения которых в литературе проработана достаточно глубоко.
В дальнейшем под лексическим анализом будем понимать процесс
предварительной обработки
исходной программы, на котором основные лексические единицы
программы - лексемы: ключевые (служебные) слова, идентификаторы, метки, константы приводятся к единому формату и
заменяются условными кодами
или ссылками на соответствующие таблицы, а комментарии исключаются из текста программы.
Выходами лексического анализа являются поток образов лексем-дескрипторов и таблицы, в последних хранятся значения выделенных в программе лексем.
Дескриптор — это пара вида: (<тип лексемы>, <указатель>),
где <тип лексемы> — это, как правило, числовой код класса лексемы, который означает, что лексема принадлежит одному из конечного множества классов слов, выделенных в языке программирования;
<указатель> — это может быть либо начальный адрес области основной памяти, в которой хранится адрес этой лексемы, либо число, адресующее элемент таблицы, в которой хранится значение этой лексемы.
Количество классов лексем (т.е. различных видов слов) в языках программирования может быть различным. Наиболее распространенными классами являются:
- идентификаторы;
- служебные (ключевые) слова;
- разделители;
- константы.
Все они присутствуют в данной программной модели.
Могут вводиться и другие классы. Это обусловлено в первую очередь той ролью, которую играют различные виды слов при написании исходной программы и, соответственно, при переводе ее в машинную программу. При этом наиболее предпочтительным является разбиение всего множества слов, допускаемого в языке программирования, на такие классы, которые бы не пересекались между собой. В этом случае лексический анализ можно выполнить более эффективно. В общем случае все выделяемые классы являются либо конечными (ключевые слова, разделители и др.) — классы фиксированных для данного языка программирования слов, либо бесконечными или очень большими (идентификаторы, константы, метки) — классы переменных для данного языка программирования слов.
С этих позиций коды образов лексем (дескрипторов) из конечных классов всегда одни и те же в различных программах для данного компилятора. Коды же образов лексем из бесконечных классов различны для разных программ и формируются каждый раз на этапе лексического анализа.
В ходе лексического анализа значения лексем из бесконечных классов помещаются в таблицы соответствующих классов. Конечность таблиц объясняет ограничения, существующие в языках программирования на длины (и соответственно число) используемых в программе идентификаторов и констант. Необходимо отметить, что числовые константы перед помещением их в таблицу могут переводиться из внешнего символьного во внутреннее машинное представление. Содержимое таблиц, в особенности таблицы идентификаторов, в дальнейшем пополняется на этапе семантического анализа исходной программы и используется на этапе генерации объектной программы.
Первоначально в тексте исходной программы лексический анализатор выделяет последовательность символов, которая по его предположению должна быть словом в программе, т.е. лексемой. Может выделяться не вся последовательность, а только один символ, который считается началом лексемы. Это наиболее ответственная часть работы лексического анализатора. Пользователю необходимо учитывать, что метка (если она присутствует) начинается сначала строки (пробелы – если они есть – во внимание не принимаются), и от операций отделяется символом “:”
Пример:
М: moveq #123,D1;
add D1,D2;
причём количество пробелов “:”до, после “:”, между операндами, между командой и операндами (и их наличие) может быть произвольным. Обязательной является “,” между приёмником и источником. В конце мнемоники команды в обязательном порядке должна стоять “;”, которая отделяет мнемокод от комментариев пользователя, которые интерпретатором игнорируются. В противном случае произойдёт выработка исключительной ситуации, о чём появится на экран соответствующее сообщение.
После этого проводится идентификация лексемы. Она заключается в сборке лексемы из символов, начиная с выделенного на предыдущем этапе, и проверки правильности записи лексемы данного класса.
Идентификация лексемы из конечного класса выполняется путем сравнения ее с эталонным значением. Основная проблема здесь — минимизация времени поиска эталона. В общем случае может понадобиться полный перебор слов данного класса, в особенности для случая, когда выделенное для опознания слово содержит ошибку. Уменьшить время поиска можно, используя различные методы ускоренного поиска:
- метод линейного списка;
- метод упорядоченного списка;
- метод расстановки и другие.
Для идентификации лексем из бесконечных (очень больших) классов используются специальные методы сборки лексем с одновременной проверкой правильности написания лексемы. При построении этих алгоритмов широко применяется формальный математический аппарат — теория регулярных языков, грамматик и конечных распознавателей. В данном случае – время поиска не актуально, так как оно и так не высоко из-за не очень большого количества команд микропроцессора.
При успешной идентификации значение лексемы из бесконечного класса помещается в таблицу идентификации лексем данного класса. При этом необходимо предварительно проверить: не хранится ли там уже значение данной лексемы, т.е. необходимо проводить просмотр элементов таблицы. Если ее там нет, то значение помещается в таблицу. При этом таблица должна допускать расширение. Опять же для уменьшения времени доступа к элементам таблицы она должна быть специальным образом организована, при этом должны использоваться специальные методы ускоренного поиска элементов.
После проведения успешной идентификации лексемы формируется ее образ — дескриптор, он помещается в выходной поток лексического анализатора. В случае неуспешной идентификации формируются сообщения об ошибках в написании слов программы.
В ходе лексического анализа осуществляются и другие виды лексического контроля, в частности, проверяется парность скобок, допустимость и правильность записи способов адресации.
Выходной поток с лексического анализатора в дальнейшем поступает на вход синтаксического анализатора. Имеется две возможности их связи:
- раздельная связь, при которой выход лексического анализатора формируется полностью и затем передается синтаксическому анализатору;
- нераздельная связь, когда синтаксическому анализатору требуется очередной образ лексемы, он вызывает лексический анализатор, который генерирует требуемый дескриптор и возвращает управление синтаксическому анализатору.
Второй вариант характерен для однопроходных трансляторов, который и реализуется в данной модели. Таким образом, процесс лексического анализа может быть достаточно простым, но в смысле времени компиляции оказывается довольно долгим. Больше половины времени, затрачиваемого компилятором на компиляцию, приходится на этап лексического анализа. Несмотря на это, данный способ позволяет успешно решать задачи, поставленные пользователем перед программой.
ЗаключениеЦелью данной работы являлось изучение организации 32-разрядного микропроцессора фирмы Motorola. Данная цель была достигнута посредством написания программной модели данного микропроцессора.
В ходе работы большое внимание уделено функциональным особенностям объекта разработки, способам организации, системе команд, представлению исходных данных в различных системах исчисления. Данное программное изделие может быть использовано при обучении студентов. Наглядный интерфейс, простота в работе, широкие возможности позволяют лучше понять структуру микропроцессора. Объектно – ориентированные методы написания программной модели позволяют в дальнейшем усовершенствовать её структуру, превратив тем самым программную модель микропроцессора в программную модель микро ЭВМ.
Список использованных источников
1. Internet. Сайты, посвящённые микроэлектронике, в частности www.Gaw.ru, раздел посвящённый микропроцессорам.
2. Жмакин А.П. Курс лекций по микропроцессорам.
3. Фаронов В.В. Delphi 5. Учебный курс, М., “Knowledge”, 2001 год.
4 Юров. В. Assembler., Санкт-Петербург: Питер” 2000 г.
5. Фаронов В. В. Delphi 5. Учебный курс.-М.: «Нолидж», 2001. –608 с., ил.
6. Архангельский А. Я. Программирование в Delphi 4 – М.: ЗАО “Издательство БИНОМ”, 1999 г. – 768 с., ил.
7. Дантеман Джефф, Мишел Джим, Тейлор Дон. Программирование в среде Delphi: Пер с англ. / Дантеманн Джефф, Тейлор Джон. – К.:НИПФ “ДиаСофтЛтд.”, 1995. – 608 с.
8. Фёдоров А. Г. Создание Windows – приложений в среде Delphi: - М.: ТОО фирма “КомпьютерПресс”, 1995. – 287 с., с ил.
9. Проектирование аппаратных и программных средств переработки информации./ Методические указания для выполнения работы бакалавра. – КГТУ. Курск.
10. Лишнер Р. Секреты Delphi 2: Пер. с англ. – Киев НИФП “ДиаСофтЛтд”, 1996. – 800 с.
