

 Курсовая работа: Використання функціонального підходу при програмуванні розподілених задач для кластеру на прикладі технології DryadLINQ
Курсовая работа: Використання функціонального підходу при програмуванні розподілених задач для кластеру на прикладі технології DryadLINQ
На рис. 1.4 показано базову архітектуру програми що використовує SOA модель програмування.
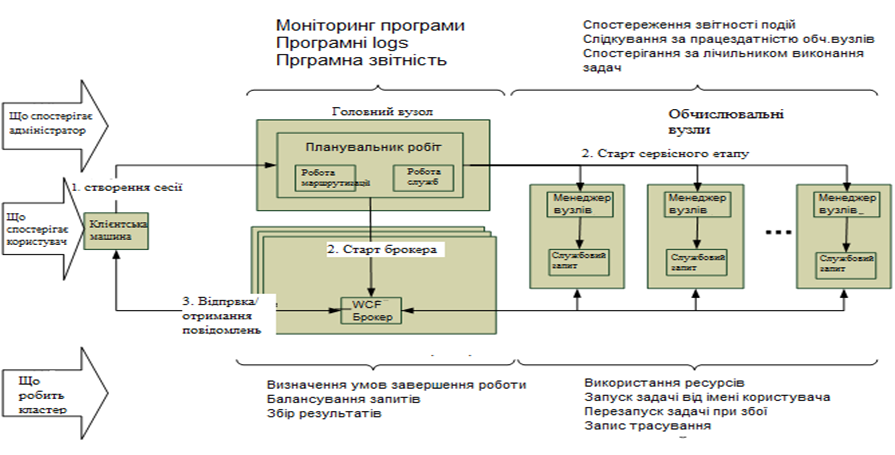
Рис. 1. 4. Базова архітектура SOA програми.
Життєвий цикл роботи на кластері Windows HPC можна виділити три основні етапи:
1. Створення сесії клієнтом.
2. Планувальник завдань виділяє вузли і запускає сервіс, який завантажує служби динамічної бібліотеки (DLL-файли). Планувальник завдань виділяє вузол Брокер, щоб почати роботу WCF Брокера. Запускаються задачі на вузлах та на WCF брокері встановлюються endpoints (умови завершення задач).
3. Клієнт отримує повідомлення про стан виконання задач на кластері та WCF брокер слідкує за рівномірним навантаженням на вузли кластера.
Адміністратор може використовувати Windows HPC Server 2008 Administrator Console для моніторингу кластера та планувальник для слідкування за прогресом і виділеними ресурсами для кожної роботи.
1.4 Технологія Dryad та DryadLinq як розширення LinqToObjectDryad - високопродуктивний двигун загального призначення для розподілених обчислень, для запуску розподілених програм на різних кластерних технологіях, у тому числі Windows HPC Server 2008. Dryad почали розробляти в Microsoft починаючи з 2006 року. Dryad спрощує завдання реалізації розподілених програм:
- Двигун Dryad виконує деякі з найбільш складних аспектів великомасштабних розподілених програм, у тому числі доставки даних в потрібне місце, планування ресурсів, оптимізації та виявлення збоїв і відновлення.
- Dryad підтримує моделі програмування, яка призначені для програмування під кластер.
- Dryad може оперувати великомасштабними об’ємами даних при паралельних обчисленнях.
dryadlinq програмування функціональний підхід
Для використання технології Dryad на кластерах Microsoft HPC створено розширення LINQ, що отримало назву DryadLinq. DryadLINQ - розширена версія мови інтегрованих запистів LINQ. Велика частина коду в типовому застосуванні DryadLINQ подібно до того, який використовується LinqToObject. DryadLinq використовують DryadLinq API; всі взаємодії програми з Dryad реалізуються через провайдер DryadLinq. Архітектуру DryadLinq можна представити у вигляді схеми зображеної на рис. 1. 5.
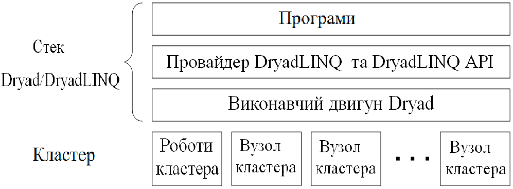
Рис. 1.5. Архітектура DryadLinq.
Application Layer (рівень програми). Програми на DryadLinq компілюються в проміжний код і використовують DryadLINQ API для частин програми що базуються на Dryad. Програми в основному пишуться на C#, проте можна використовувати інші середовища, що підтримують Linq, наприклад F#.
DryadLINQ API and provider. DryadLinq надає розширену версію LINQ API яку використовують програми для реалізації запитів. Провайдер DryadLinq конвертує запити в роботу Dryad і виконує роботу на кластері.
Dryad execution engine (виконавчий двигун Dryad). Виконавчий двигун Dryad керує виконанням кожної роботи Dryad на кластері.
Server cluster (кластер) На кластері роботи виконуються на певних вузлах. За виконанням робіт слідкує JobManager на головному вузлі кластера.
Застосування Dryad розміщується клієнтському комп'ютері, що підключений до кластеру мережевим з'єднанням. Велика частина коду програми, такі як користувальницький інтерфейс зазвичай виконується на робочій станції. Ті частини програми, що використовують Dryad упаковані в якості роботи Dryad і виконується на кластері. Роботи Dryad є механізмом для виконання розподілених програм на кластері. На рис. 1. 6 представлена схема роботи простої розподіленої програми такої як множення на константу кожного елемента масиву.
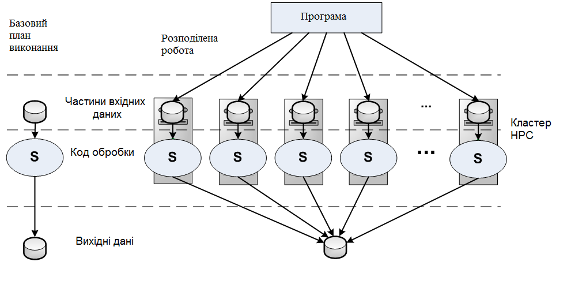
Рис. 1.6 Схема роботи простої розподіленої програми.
Зліва відображається головний виконавчий план, тобто як ця робота буде виконуватися на одному комп’ютері, проте розподілена робота буде виконуватися наступним чином:
Вхідні дані розбиваються на виконавчі частини, і кожна частина копіюється в один з обчислювальних вузлів.
Окремий примірник коду обробки направляється кожного обчислювального вузла.
Всі обчислювальні вузли одночасно обробляють дані з своїх виконавчих частин.
Оброблені виконавчі частини складаються один набір даних, і повертаються клієнтський програмі.
Дана діаграма на рисунку в загальному демонструє роботу DryadLinq, проте якщо розглянути це більш детально, то DryadLinq використовує механізм схожий на "UNIX piping mechanism" для зв’язку між різними процесами Dryad. Виконавчий план роботи Dryad являє собою направлений ациклічний граф, вершинами якого є незалежні процеси що працюють з даними лише зі свого рівняю. Для нескладної задачі цей граф буде мати наступний вигляд:
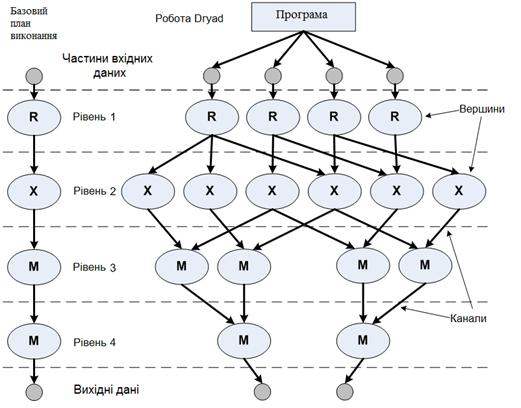
Рис. 1.7. Виконавчий план роботи Dryad.
З ліва відображається головний виконавчий план, тобто виконання роботи на одному комп’ютері. З права - виконання розподіленої роботи як мінімум на 6 вузлах кластера. Розглянемо це більш детально:
Розподілення вхідних даних (Input data partitions). Робота Dryad починається з колекцією вхідних даних, такі як log файл наприклад. Вхідні дані розбиваються на частини і копіюються на вузли кластера. (Дана версія DryadLinq не розбиває дані і не копіює їх на вузли, це необхідно робити окремо)
Рівень (Stage). Робота Dryad складається з одного або більше рівнів. Кожен рівень відповідає елементу основного плану виконання.
Вершина (Vertex). Кожен рівень складається з одного або більше однакових вершин. Кожна вершина є незалежним екземпляром коду обробки даних певного рівня, і використовує дані лише зі свого рівня. Вершини мають певні особливості:
- Різні етапи можуть мати різне число вершин.
- Якщо на певному рівні використовуються статичні дані, число вершин диктується кількістю наданих частин даних. Якщо є більше розділів з даними, ніж робочих комп'ютерів, Dryad використовує кілька проходів для обробки даних.
- Певний тип вершини може бути використаний на декількох рівнях.
- Для DryadLINQ, кожна вершина використовують методи Microsoft.net Framework.
- Кожна вершина зазвичай виконується на окремому обчислювальному вузлі.
Канал (Channel). Дані на кожному наступному рівні беруться з попереднього за допомогою каналів. Для цього DryadLINQ використовує два механізма: файли та спільної пам'яті. Спільну пам'ять каналів іноді називають спільною пам'ятю FIFO каналів (перший увійшов, перший вийшов). Деякі вказівки:
- DryadLINQ пересилає дані за допомогою файлу, що є найбільш гнучким для канального типу. DryadLINQ використовує спільну пам'ять тільки для певних сценаріїв.
- вершина може мати канал для більш ніж однієї вершини в наступному рівні.
- Різні види каналів можуть бути використані у різних частинах графу.
- Канали підключаються до вершин, так що граф є ациклічним.
- Канали працюють за принципом точка-точка. Вони пов'язують вихід з однієї вершини з входом іншої вершини.
Кількість вершин на кожному рівні та к-сть каналів що їх поєднує вибирається з міркувань оптимізації та швидкодії. В додаток, Dryad може динамічно змінювати певні рівні графу для покращення продуктивності виконання роботи. Ефективність роботи DryadLINQ трохи нижче, ніж при застосуванні Dryad API, проте різниця відносно невелика.
2. Реалізації розподіленої програми з використанням DryadLINQ 2.1 Структура та налаштування кластерної системи
На рис. 2. 1 представлена принципова схема, як Dryad виконує роботу.
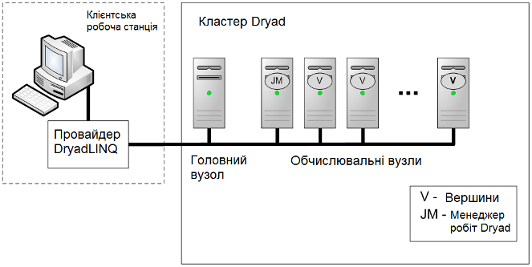
Рис. 2.1. Схема виконання роботи Dryad.
Користувач запускає програму що використовує DryadLINQ з клієнтської робочої станції. Після створення виконавчого графу, менеджер робіт Dryad створює роботу з запитів DryadLINQ та запускає роботу в кластері Windows HPC. Менеджер робіт Dryad - задача Windows HPC на головному вузлі, яка керує виконанням відповідної роботи на кластері. Зокрема, робота менеджера породжує вершини, що є завданнями, які належать до однієї роботи на Windows HPC.
Програмне забезпечення Dryad встановлене на всіх комп’ютерах кластера для того щоб виконувати певні деталі роботи Dryad. На головному вузлі встановлено головна частина программного забезпечення Dryad, що включає в себе наступне: менджер робіт, менеджер вузлів та ін. Від вузлів вимагається тільки обробляти дані що містяться на них. Тобто кожен вузол має копію частини програми що працює з колекцією даних.
Кластерна програма на основі Dryad залежать від:
клієнтської робочої станції.
Обчислювальні вузли.
комп’ютерів чи бази даних, на яких розміщуються дані.
Все має бути правильно налаштовано для того щоб програма на Dryad нормально працювала.
При застосуванні DryadLINQ, програма повинна мати можливість переміщення даних між вузлами кластера які, в свою чергу, повинні мати відповідний доступ до один одного. Загалом DryadLINQ вимагає привілеї високого рівня. Якщо робота DryadLINQ що запущена на кластері повертає помилку з кодом один, то зазвичай це недостатність прав користувача або відсутність певного ресурсу з відповідним доступом. Тобто необхідним для виконання роботи Dryad на кластері є права користувача на можливість погодження і запуску роботи на кластері, а також права доступу до вхідних даних.
Стандартні папки вводу виводу
При встановленні програмного комплексу Dryad автоматично створюються і відкривається доступ до наступних папок на кожному вузлі, а також на головному вузлі кластера:
- DryadData - для розташування вхідних даних
- XC - для збереження проміжних даних що створюються роботою Dryad
- XC\output - використовується як папка за замовчуванням для вихідних даних (якщо ви не хочете використовувати цю папку для виведення даних, то її можна змінити у файлі конфігурації DryadLINQ)
2.2 Файли конфігураціїКожен проект DryadLINQ повинен включати в себе файл конфігурації DryadLinqConfig. xml. Файли конфігурації поділяються на:
- Глобальний DryadLinqConfig. xml - містить налаштування що не змінюються в залежності від проекту (наприклад ім’я головного вузла, стандартні папки вводу виводу). Він міститься в C: \Program Files\Microsoft Research DryadLINQ
- Локальний DryadLinqConfig. xml - налаштування для певної розподіленої програми. Цей файл знаходиться в папці проекту програми разом з виконавчими файлами.
Розглянемо вміст глобального файлу конфігурації. Для даного кластера він приймає наступний вигляд:
<DryadLinqConfig>
<ClusterName>hnode</ClusterName>
<Cluster name="hnode"
schedulertype="Hpc"
partitionuncdir=" XC\output "
dryadoutputdir="file: // \\hnode\Userdata\tmaliarchuk\output" />
</DryadLinqConfig>
Розберемо по частинам:
- hnode - ім’я головного вузла кластера
- XC\output - папка для збереження проміжних даних що створюються роботою Dryad
- file: // \\hnode\Userdata\tmaliarchuk\output - папка виводу результату
Як вже було зазначено локальний файл конфігурації знаходиться в папці проекту, він містить тільки шлях до глобального файлу конфігурації:
<DryadLinqConfig>
<DryadLinqRoot>
C: \Program Files\Microsoft Research DryadLINQ
</DryadLinqRoot>
</DryadLinqConfig>
За замовчуванням це C: \Program Files\Microsoft Research DryadLINQ.
2.3 Представлення колекцій данихДані в роботі Dryad необхідно представити у вигляді колекції. Для звичайного запитів LinqToObject це тип IEnumerable<T>. Це так би мовити колекція даних типу Т над якою можна виконувати такі операції як сортування, видобуток та інші функції які доступні в бібліотеці System. Linq. Проте після перелічених операції робота Dryad повертає не об’єкт типу IEnumerable<T>, а IQueryable<T>. IQueryable<T> наслідує IEnumerable<T>, проте ці два типи колекцій працюють по різному:
IEnumerable<T> - представляється як ітератор по колекції даних, які знаходяться на комп’ютері. Під час виконання програми об’єкт колекції компілюються локальним.net JIT компілятором, і ітератори використовуються для покращення виконання програми локально.
IQueryable<T> - представляється як запит по колекції даних. Під час виконання програми об’єкт колекції передається провайдеру DryadLINQ що транслює запити в роботу Dryad і повертає вже оброблені дані до програми. Це використовується для розподілених програм на кластері.
Під час виконання роботи Dryad на кластері вхідні дані представляються у вигляді PartitionedTable<T>. PartitionedTable<T> наслідує IQueryable<T>, а отже наслідує і всі методи IQueryable<T>. PartitionedTable<T> представляє дані ніби вони знаходяться на одному вузлі, проте в реальності вони розділені на частини та знаходяться не на одному вузлі.
2.4 Файл метаданих
Як вже було зазначено даний версія DryadLINQ не підтримує автоматичне розбиття даних та копіювання їх на вузли. Це необхідно зробити самостійно, або програмно, написавши додаткові процедури що будуть це виконувати. Отже множина розподілених даних полягає в наступних файлах:
- файл метаданих, який являться текстовим файлом що містить метадані які описують розподілені дані
- множини розподілених даних, вони можуть бути будь якого зручного для вашої програми формату включно бінарний формат.
Файл метеданих може приймати наступний вигляд (у випадку виконання роботи на 4 вузлах):
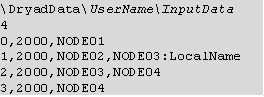
Файл метаданих має формат. pt і містить три розділи:
- папка та ім’я файлу - перша строчка описує стандартну папку з відкритим доступом і стандартне ім’я для часткових даних. Кожен вузол в кластері має папку DryadData з відповідними правами доступу та кожна частина розподілених даних повинна міститися в цій папці на відповідних вузлах
- кількість частин - друга строчка описує кількість частин розподілених даних. В даному випадку 4
- опис розподілених даних - решта файлу. Одна строка - на одну частину. Кожна лінія містить три або більше елементів розподілених комою: номер частини даних (в десятковому вигляді), розмір частини, ім’я комп’ютерів де знаходяться ці дані.
У файлі метеданих не повинно бути жодних пробілів. Номер частин розподілених починається з 00000000. Розмір частини вказувати не обов’язково, тобто якщо при кожному новому виконанні роботи Dryad її розмір змінюється можна вказати нульовий розмір. Також певна чатина даних може не знаходитися в стандартній папці. У цьому випадку в рядку опису цієї частини після переліку вузлів де знаходиться ця частина необхідно поставити ": " та потім вказати ім’я папки та ім’я частини. Наприклад у випадку використання тільки однієї частини розподілених даних файл метаданих може бути наступним

Тут ми не вказуємо папку та ім’я за замовчуванням.
2.5 Бібліотеки LinqToDryad. dll та System. Threading. dllТакож проект що використовує DryadLINQ необхідно підключити дві бібліотеки LinqToDryad. dll та System. Threading. dll. LinqToDryad. dll містить клас бібліотек DryadLINQ та провайдер DryadLINQ. Розташування цієї бібліотеки за замовчуванням C: \Program Files\Microsoft Research DryadLINQ\lib де міститься версії цієї бібліотеки для відлагодження та для кінцевої версії проекту. System. Threading. dll стандартна бібліотека платформи.net 3. 5 необхідна для використання стандартних можливостей цієї платформи (наприклад WCF). Розташовується вона за замовчуванням в С: \Program Files\Microsoft Research DryadLINQ\Lib\Microsoft\Framework\v3. 5\
2.6 Виконання роботи Dryad
Для реалізації консольної програми обчислення інтегралу 1/х методом Монте-Карло на кластері Windows HPC 2008 з використанням DryadLINQ програма перед початком роботи генерує випадкові точки в певному діапазоні записує їх у декілька текстових файлів кожен з яких потім копіюється на відповідний вузол.
Розглянемо виконання роботи Dryad на прикладі запиту DryadLINQ
PartitionedTable<LineRecord> table = PartitionedTable. Get<LineRecord> (uri);
IQueryable<string> table1 = table
. Select (s => s. line)
. Where (s => (1/ (fun (s. Split (' ') [0]))) > fun (s. Split (' ') [1]));
double result = (1. 000000 * table1. Count () * (x2-x1) * (y2-y1)) /lenght;
Спочатку зчитується файл метаданих де вказується кількість та місце знаходження частин розподілених даних які попередньо були скопійовані на відповідні вузли. Далі представляється IQueryable<string> у вигляді PartitionedTable<string>. В запиті DryadLINQ реалізується вибірка тих текстових рядків в яких функція 1/x від першого числа більша за друге число. Тут використовується функція fun яка переводить string у double та функція Split з простору System. Text що розділяє стрічку на частини між якими був знак пробілу. Це реалізується двома методами Select та Where. Перший серед всієї сукупності вхідних діних виділяє рядок, а другий аналізує чи цей рядок задовольняє нашим умовам. Після цього підраховується кількість обраних рядків за допомогою методу Count.
Під час виконання роботи Dryad на консолі провайдер Dryad виводить наступне:
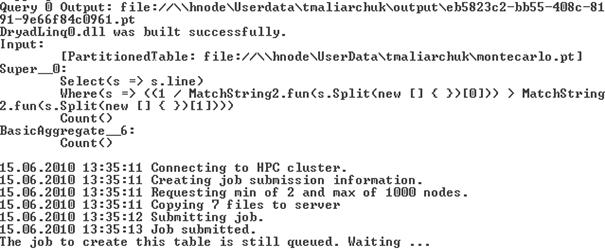
Рис. 2.2
Як видно з рисунка провайдер Dryad виводить:
- шлях стандартної папки виводу
- місце знаходження файлу метаданих
- елементи кожного рівня виконавчого графа Dryad
- інформація про стан підключення до кластера та погодження роботи на ньому
- інформується чи робота виконується (running) чи вона поки що в черзі (queued)
Після завершення виконання роботи Dryad на кластері провайдер Dryad повертає оброблені дані до програми.
Дана програма обчислення інтегралу методом Монте-Карло була запущена на різній кількості вузлів: від одного до шести.
![]()
|
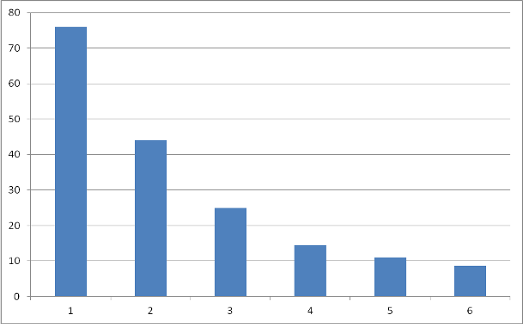
Рис. 2.3. Залежність часу виконання роботи Dryad від кількості задіяних вузлів.
Висновки
В результаті зробленого аналізу підходів до розробки паралельних програм було обґрунтовано доцільність створення нового, який передбачає покладання фонової роботи по розпаралеленню на інструментальні засоби, а не на розробника. Серед існуючих парадигм програмування було обрано парадигму функціонального програмування як таку що відповідає висунутим критеріям.
Внаслідок аналізу інструментальних засобів для створення функціонально орієнтованих програм було обрано DryadLINQ.
Реалізована обчислювальна задача методом Монте-Карло дозволила сформувати концепцію використання функціонального підходу у програмуванні для реалізації паралельних обчислювальних задач.
Перелік посилань
1. Windows® HPC Server 2008 Resource Kit: // http://resourcekit. windowshpc.net/home.html
2. DryadLINQ - Microsoft Research Project Page // http://research. microsoft.com/en-us/projects/dryadlinq/
3. Microsoft® Connect – Dryad // http://connect. microsoft.com/Dryad
4. Dryad - Microsoft Research Project Page // http://research. microsoft.com/en-us/projects/dryad/
5. Dryad and DryadLINQ for Data Intensive Research // http://research. microsoft.com/en-us/collaboration/tools/dryad. aspx
6. Intel - HPC: архитектура суперкомпьютеров и разновидности // http://ru. intel.com/business/community/? automodule=blog&blogid=6276&showentry=888
7. Russian Software Developer Network // http://www.rsdn.ru/
8. Language-Integrated Query (LINQ) // http://msdn. microsoft.com/en-us/library/bb397926. aspx
9. LINQ:.net Language-Integrated Query // http://msdn. microsoft.com/en-us/library/bb308959. aspx
10. Dryad and DryadLINQ team blogs // http://blogs. msdn.com/b/dryad/
11. Meijer E., Barga R. Introduction to Dryad and DryadLINQ // http://channel9. msdn.com/posts/Charles/Expert-to-Expert-Erik-Roger-Barga-Introduction-to-Dryad-and-DryadLINQ/
12. Vert J. Data-Intensive Computing on Windows HPC Server with the DryadLINQ Framework // http://microsoftpdc.com/Sessions/SVR17
13. Podwysocki M. Dryad/DryadLINQ and Project Trident Released
14. // http://weblogs. asp.net/podwysocki/archive/2009/07/16/dryad-dryadlinq-and-project-trident-released. aspx
15. Campbell D. Dryad and DryadLINQ: Academic Accelerators for Parallel Data Analysis // http://blogs. msdn.com/b/msr_er/archive/2010/02. aspx
16. Colaci A. Dryad and DryadLINQ for Data Intensive Research // http://blogs. msdn.com/b/lchong/archive/2009/09/23/dryad-and-dryadlinq-for-data-intensive-research. aspx
17. Chong L. Scaling out PLINQ: DryadLINQ at PDC09 and Supercomputing09 // http://blogs. msdn.com/b/pfxteam/archive/2009/11/11/9921066. aspx
Додатки
Додаток А
Текст глобального файлу конфігурації
<DryadLinqConfig>
<ClusterName>hnode</ClusterName>
<Cluster name="hnode"
schedulertype="Hpc"
partitionuncdir=" XC\output "
dryadoutputdir="file: // \\hnode\Userdata\tmaliarchuk\output" />
</DryadLinqConfig>
Текст локального файлу конфігурації
DryadLinqConfig>
<DryadLinqRoot>
C: \Program Files\Microsoft Research DryadLINQ
</DryadLinqRoot>
</DryadLinqConfig>
Текст файлу метаданих (у випадку чотирьох обчислювальних вузлів)
\DryadData\tmaliarchuk\mc
4
0,0,NODE05
1,0,NODE06
2,0,NODE10
3,0,NODE14
Текст програми обрахунку інтегралу методом Монте-Карло
using System;
using System. IO;
using System. Collections. Generic;
using System. Text;
using System. Linq;
using LinqToDryad;
using System. Diagnostics;
public class MatchString2
{
public static double fun (string s)
{
int i, j = 1;
double ds = 0;
bool b = false;
for (i = 0; (i! = (s. Length)); i++)
{
if (s [i]! = ',')
if (! b) ds = ds*10 + ( (int) s [i] - 48);
else
{
j *= 10;
ds = ds + (1. 0000 * ( (int) s [i] - 48) / j);
}
else b = true;
}
return ds;
}
public static void create (int lenght, int x1, int x2, int y1, int y2, string source,string destination)
{
Console. WriteLine (source);
Random rnd = new Random ();
using (StreamWriter sw = new StreamWriter (source))
{
for (int i = 0; i < lenght / 2; i++)
{
sw. Write (Convert. ToString (x1 + (x2 - x1) * rnd. NextDouble ()));
sw. Write (' ');
sw. WriteLine (Convert. ToString (y1 + (y2 - y1) * rnd. NextDouble ()));
}
}
Console. WriteLine ("copying");
System. IO. File. Copy (source, destination, true);
}
static void Main (string [] args)
{
int lenght = 1000000;
int x1 = 1;
int x2 = 10;
int y1 = 0;
int y2 = 1;
create (lenght/4, x1, x2, y1, y2, @"D: \temp\mc. 00000000", "\\\\node05\\DryadData\\tmaliarchuk\\mc. 00000000");
create (lenght/4, x1, x2, y1, y2, @"D: \temp\mc. 00000001", "\\\\node06\\DryadData\\tmaliarchuk\\mc. 00000001");
create (lenght/4, x1, x2, y1, y2, @"D: \temp\mc. 00000002", "\\\\node10\\DryadData\\tmaliarchuk\\mc. 00000002");
create (lenght/4, x1, x2, y1, y2, @"D: \temp\mc. 00000003", "\\\\node14\\DryadData\\tmaliarchuk\\mc. 00000003");
string uri = DataPath. FileUriPrefix + Path.combine ("\\\\hnode\\UserData\\tmaliarchuk", "montecarlo. pt");
PartitionedTable<LineRecord> table = PartitionedTable. Get<LineRecord> (uri);
Stopwatch t = new Stopwatch ();
t. Start ();
IQueryable<string> table1 = table. Select (s => s. line)
. Where (s => (1/ (fun (s. Split (' ') [0]))) > fun (s. Split (' ') [1]));
double result = (1. 000000 * table1. Count () * (x2-x1) * (y2-y1)) /lenght;
t. Stop ();
Console. WriteLine (t. Elapsed);
Console. WriteLine (result);
Console. ReadKey ();
}
}
