

 Доклад: Сравнительные характеристики современных аппаратных платформ
Доклад: Сравнительные характеристики современных аппаратных платформ
В процессоре PA 7200 реализован эффективный алгоритм предварительной выборки команд, хорошо работающий и на линейных участках программ.
Как и в PA 7100 в процессоре реализован интерфейс с внешней кэш-памятью данных, работающей на тактовой частоте процессора с однотактным временем ожидания. Внешняя кэш-память данных построена по принципу прямого отображения. Кроме того, для повышения эффективности на кристалле процессора реализован небольшой вспомогательный кэш емкостью в 64 строки. Формирование, преобразование адреса и обращение к основной и вспомогательной кэш-памяти данных выполняется на двух ступенях конвейера. Максимальная задержка при обнаружении попадания равна одному такту.
Вспомогательный внутренний кэш содержит 64 32-байтовые строки. При обращении к кэш-памяти осуществляется проверка 65 тегов: 64-х тегов вспомогательного кэша и одного тега внешнего кэша данных. При обнаружении совпадения данные направляются в требуемое функциональное устройство.
При отсутствии необходимой строки в кэш-памяти производится ее загрузка из основной памяти. При этом строка поступает во вспомогательный кэш, что в ряде случаев позволяет сократить количество перезагрузок внешней кэш-памяти, организованной по принципу прямого отображения. Архитектурой нового процессора для команд загрузки/записи предусмотрено кодирование специального признака локального размещения данных ("spatial locality only"). При выполнении команд загрузки, помеченных этим признаком, происходит обычное заполнение строки вспомогательного кэша. Однако последующая запись строки осуществляется непосредственно в основную память минуя внешний кэш данных, что значительно повышает эффективность работы с большими массивами данных, для которых размера строки кэш-памяти с прямым отображением оказывается недостаточно.
Расширенный набор команд процессора позволяет реализовать средства автоиндексации для повышения эффективности работы с массивами, а также осуществлять предварительную выборку команд, которые помещаются во вспомогательный внутренний кэш. Этот вспомогательный кэш обеспечивает динамическое расширение степени ассоциативности основной кэш-памяти, построенной на принципе прямого отображения, и является более простым альтернативным решением по сравнению с множественно-ассоциативной организацией.
Процессор PA 7200 включает интерфейс новой 64-битовой мультиплексной системной шины Runway, реализующей расщепление транзакций и поддержку протокола когерентности памяти. Этот интерфейс включает буфера транзакций, схемы арбитража и схемы управления соотношениями внешних и внутренних тактовых частот.
PA-8000
Процессор PA-8000 был анонсирован в марте 1995 года на конференции COMPCON 95. Было объявлено, что показатели его производительности будут достигать 8.6 единиц SPECint95 и 15 единиц SPECfp95 для операций целочисленной и вещественной арифметики соответственно. В настоящее время этот очень высокий уровень производительности подтвержден испытаниями рабочих станций и серверов, построенных на базе этого процессора.
Процессор PA-8000 вобрал в себя все известные методы ускорения выполнения команд. В его основе лежит концепция "интеллектуального выполнения", которая базируется на принципе внеочередного выполнения команд. Это свойство позволяет PA-8000 достигать пиковой суперскалярной производительности благодаря широкому использованию механизмов автоматического разрешения конфликтов по данным и управлению аппаратными средствами. Эти средства хорошо дополняют другие архитектурные компоненты, заложенные в структуру кристалла: большое число исполнительных функциональных устройств, средства прогнозирования направления переходов и выполнения команд по предположению, оптимизированная организация кэш-памяти и высокопроизводительный шинный интерфейс.
Высокая производительность PA-8000 во многом определяется наличием большого набора функциональных устройств, который включает в себя 10 исполнительных устройств: два арифметико-логических устройства (АЛУ) для выполнения целочисленных операций, два устройства для выполнения операций сдвига/слияния данных, два устройства для выполнения умножения/сложения чисел с плавающей точкой, два устройства деления/вычисления квадратного корня и два устройства выполнения операций загрузки/записи.
Средства внеочередного выполнения команд процессора PA-8000 обеспечивают аппаратное планирование загрузки конвейеров и лучшее использование функциональных устройств. В каждом такте на выполнение могут выдаваться до четырех команд, которые поступают в 56-строчный буфер переупорядочивания. Этот буфер позволяет поддерживать постоянную занятость функциональных устройств и обеспечивает эффективную минимизацию конфликтов по ресурсам. Кристалл может анализировать все 56 командных строк одновременно и выдавать в каждом такте по 4 готовых для выполнения команды в функциональные устройства. Это позволяет процессору автоматически выявлять параллелизм уровня выполнения команд.
Суперскалярный процессор PA-8000 обеспечивает полный набор средств выполнения 64-битовых операций, включая адресную арифметику, а также арифметику с фиксированной и плавающей точкой. При этом кристалл полностью сохраняет совместимость с 32-битовыми приложениями. Это первый процессор, в котором реализована 64-битовая архитектура PA-RISC. Он сохраняет полную совместимость с предыдущими и будущими реализациями PA-RISC.
Кристалл изготовлен по 0.5-микронной КМОП технологии с напряжением питания 3.3 В и можно рассчитывать на дальнейшее уменьшение размеров элементов в будущем.
Особенности архитектуры MIPS компании MIPS Technology
Архитектура MIPS была одной из первых RISC-архитектур, получившей признание со стороны промышленности. Она была анонсирована в 1986 году. Первоначально это была полностью 32-битовая архитектура, которая включала 32 регистра общего назначения, 16 регистров плавающей точки и специальную пару регистров для хранения результатов выполнения операций целочисленного умножения и деления. Размер команд составлял 32 бит, в ней поддерживался всего один метод адресации, и пользовательское адресное пространство также определялось 32 битами. Выполнение арифметических операций регламентировалось стандартом IEEE 754. В компьютерной промышленности широкую популярность приобрели 32-битовые процессоры R2000 и R3000, которые в течение достаточно длительного времени служили основой для построения рабочих станций и серверов компаний Silicon Graphics, Digital, Siemens Nixdorf и др. Процессоры R3000/R3010 работали на тактовой частоте 33 или 40 МГц и обеспечивали производительность на уровне 20 SPECint92 и 23 SPECfp92.
Затем на смену микропроцессорам семейства R3000 пришли новые 64-битовые микропроцессоры R4000 и R4400. (MIPS Technology была первой компанией выпустившей процессоры с 64-битовой архитектурой). Набор команд этих процессоров (спецификация MIPS II) был расширен командами загрузки и записи 64-разрядных чисел с плавающей точкой, командами вычисления квадратного корня с одинарной и двойной точностью, командами условных прерываний, а также атомарными операциями, необходимыми для поддержки мультипроцессорных конфигураций. В процессорах R4000 и R4400 реализованы 64-битовые шины данных и 64-битовые регистры. В этих процессорах применяется метод удвоения внутренней тактовой частоты.
Процессоры R2000 и R3000 имели стандартные пятиступенчатые конвейеры команд. В процессорах R4000 и R4400 применяются более длинные конвейеры (иногда их называют суперконвейерами). Количество ступеней в процессорах R4000 и R4400 увеличилось до восьми, что объясняется прежде всего увеличением тактовой частоты и необходимостью распределения логики для обеспечения заданной пропускной способности конвейера. Процессор R4000 может работать с тактовой частотой 50/100 МГц и обеспечивает уровень производительности в 58 SPECint92 и 61 SPECfp92. Процессор R4400 может работать на частоте 50/100 МГц, или 75/150 МГц, показывая уровень производительности 94 SPECint92 и 105 SPECfp92.
Внутренняя кэш-память процессора R4000 имеет емкость 16 Кбайт. Она разделена на 8-Кб кэш команд и 8-Кб кэш данных. С точки зрения реализации кэш-памяти процессор R4400 имеет более развитые возможности. Он выпускается в трех модификациях: PC (Primary Cashe) - имеет внутренние кэши команд и данных емкостью по 16 Кбайт. Процессор в такой конфигурации предназначен главным образом для дешевых моделей рабочих станций. SC (Secondary Cashe) содержит логику управления кэш-памятью второго уровня. MC (Multiprocessor Cashe) - использует специальные алгоритмы обеспечения когерентности и согласованного состояния памяти для многопроцессорных конфигураций.
В середине 1994 года компания MIPS анонсировала процессор R8000, который прежде всего был ориентирован на научные прикладные задачи с интенсивным использованием операций с плавающей точкой. Этот процессор построен на двух кристаллах (выпускается в виде многокристальной сборки) и представляет собой первую суперскалярную реализацию архитектуры MIPS. Теоретическая пиковая производительность процессора для тактовой частоты 75 МГц составляет 300 MFLOPs (до четырех команд и шести операций с плавающей точкой в каждом такте). Реализация большой кэш-памяти данных емкостью 16 Мбайт, высокой пропускной способности доступа к данным (до 1.2 Гбайт/с) в сочетании с высокой скоростью выполнения операций позволяет R8000 достигать 75% теоретической производительности даже при решении больших задач типа LINPACK с размерами матриц 1000x1000 элементов. Аппаратные средства поддержки когерентного состояния кэш-памяти вместе со средствами распараллеливания компиляторов обеспечивают возможность построения высокопроизводительных симметричных многопроцессорных систем. Например, процессоры R8000 используются в системе Power Challenge компании Silicon Graphics, которая вполне может сравниться по производительности с известными суперкомпьютерами Cray Y-MP, имеет на порядок меньшую стоимость и предъявляет значительно меньшие требования к подсистемам питания и охлаждения. В однопроцессорном исполнении эта система обеспечивает производительность на уровне 310 SPECfp92 и 265 MFLOPs на пакете LINPACK (1000x1000).
В 1994 году MIPS Technology объявила также о создании своего нового суперскалярного процессора R10000, начало массовых поставок которого ожидалось в конце 1995 года. По заявлениям представителей MIPS Technology R10000 обеспечивает пиковую производительность в 800 MIPS при работе с внутренней тактовой частотой 200 МГц за счет обеспечения выдачи для выполнения четырех команд в каждом такте синхронизации. При этом он обеспечивает обмен данными с кэш-памятью второго уровня со скоростью 3.2 Гбайт/с.
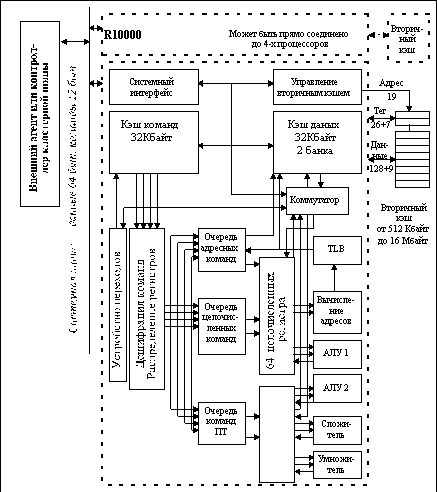
Рис. 6.12. Блок-схема микропроцессора R10000
Чтобы обеспечить столь высокий уровень производительности в процессоре R10000 реализованы многие последние достижения в области технологии и архитектуры процессоров. На рисунке 6.12 показана блок-схема этого микропроцессора.
Иерархия памяти
При разработке процессора R10000 большое внимание было уделено эффективной реализации иерархии памяти. В нем обеспечиваются раннее обнаружение промахов кэш-памяти и параллельная перезагрузка строк с выполнением другой полезной работой. Реализованные на кристалле кэши поддерживают одновременную выборку команд, выполнение команд загрузки и записи данных в память, а также операций перезагрузки строк кэш-памяти. Заполнение строк кэш-памяти выполняется по принципу "запрошенное слово первым", что позволяет существенно сократить простои процессора из-за ожидания требуемой информации. Все кэши имеют двухканальную множественно-ассоциативную организацию с алгоритмом замещения LRU.
Кэш-память данных первого уровня
Кэш-память данных первого уровня процессора R10000 имеет емкость 32 Кбайт и организована в виде двух одинаковых банков емкостью по 16 Кбайт, что обеспечивает двухкратное расслоение при выполнении обращений к этой кэш-памяти. Каждый банк представляет собой двухканальную множественно-ассоциативную кэш-память с размером строки (блока) в 32 байта. Кэш данных индексируется с помощью виртуального адреса и хранит теги физических адресов памяти. Такой метод индексации позволяет выбрать подмножество кэш-памяти в том же такте, в котором формируется виртуальный адрес. Однако для того, чтобы поддерживать когерентность с кэш-памятью второго уровня, в кэше первого уровня хранятся теги физических адресов памяти.
Массивы данных и тегов в каждом банке являются независимыми. Эти четыре массива работают под общим управлением очереди формирования адресов памяти и схем внешнего интерфейса кристалла. В очереди адресов могут одновременно находиться до 16 команд загрузки и записи, которые обрабатываются в четырех отдельных конвейерах. Команды из этой очереди динамически выдаются для выполнения в специальный конвейер, который обеспечивает вычисление исполнительного виртуального адреса и преобразование этого адреса в физический. Три других параллельно работающих конвейера могут одновременно выполнять проверку тегов, осуществлять пересылку данных для команд загрузки и завершать выполнение команд записи в память. Хотя команды выполняются в строгом порядке их расположения в памяти, вычисление адресов и пересылка данных для команд загрузки могут происходить неупорядоченно. Схемы внешнего интерфейса кристалла могут выполнять заполнение или обратное копирование строк кэш-памяти, либо операции просмотра тегов. Такая параллельная работа большинства устройств процессора позволяет R10000 эффективно выполнять реальные многопроцессорные приложения.
Работа конвейеров кэш-памяти данных тесно координирована. Например, команды загрузки могут выполнять проверку тегов и чтение данных в том же такте, что и преобразование адреса. Команды записи сразу же начинают проверку тегов, чтобы в случае необходимости как можно раньше инициировать заполнение требуемой строки из кэш-памяти второго уровня, но непосредственная запись данных в кэш задерживается до тех пор, пока сама команда записи не станет самой старой командой в общей очереди выполняемых команд и ей будет позволено зафиксировать свой результат ("выпустится"). Промах при обращении к кэш-памяти данных первого уровня инициирует процесс заполнения строки из кэш-памяти второго уровня. При выполнении команд загрузки одновременно с заполнением строки кэш-памяти данные могут поступать по цепям обхода в регистровый файл.
При обнаружении промаха при обращении к кэш-памяти данных ее работа не блокируется, т.е. она может продолжать обслуживание следующих запросов. Это особенно полезно для уменьшения такого важного показателя качества реализованной архитектуры как среднее число тактов на команду (CPI - clock cycles per instruction). На рисунке 6.13 представлены результаты моделирования работы R10000 на нескольких программах тестового пакета SPEC. Для каждого теста даны два результата: с блокировкой кэш-памяти данных при обнаружении промаха (вверху) и действительное значение CPI R10000 (внизу). Выделенная более темным цветом правая область соответствует времени, потерянному из-за промахов кэш-памяти. Верхний результат отражает полную задержку в случае, если бы все операции по перезагрузке кэш-памяти выполнялись строго последовательно. Таким образом, стрелка представляет потери времени, которые возникают в блокируемом кэше. Эффект применения неблокируемой кэш-памяти сильно зависит характеристик самих программ. Для небольших тестов, рабочие наборы которых полностью помещаются в кэш-памяти первого уровня, этот эффект не велик. Однако для более реальных программ, подобных тесту tomcatv или тяжелому для кэш-памяти тесту compress, выигрыш оказывается существенным.

Рис. 6.13. Моделирование работы R10000 на нескольких компонентах пакета SPEC
Кэш-память второго уровня
Интерфейс кэш-памяти второго уровня процессора R10000 поддерживает 128-битовую магистраль данных, которая может работать с тактовой частотой до 200 МГц, обеспечивая скорость обмена до 3.2 Гбайт/с (для снижения требований к быстродействию микросхем памяти предусмотрена также возможность деления частоты с коэффициентами 1.5, 2, 2.5 и 3). Все стандартные синхронные сигналы управления статической памятью вырабатываются внутри процессора. Не требуется никаких внешних интерфейсных схем. Минимальный объем кэш-памяти второго уровня составляет 512 Кбайт, максимальный размер - 16 Мбайт. Размер строки этой кэш-памяти программируется и может составлять 64 или 128 байт.
Одним из методов улучшения временных показателей работы кэш-памяти является построение псевдо-множествнно-ассоциативной кэш-памяти. В такой кэш-памяти частота промахов находится на уровне частоты промахов множественно-ассоциативной памяти, а время выборки при попадании соответствует кэш-памяти с прямым отображением. Кэш-память R10000 организована именно таким способом, причем для ее реализации используются стандартные синхронные микросхемы памяти (SRAM). В одном наборе микросхем памяти находятся оба канала кэша. Информация о частоте использования этих каналов хранится в схемах управления кэшем на процессорном кристалле. Поэтому после обнаружения промаха в первичном кэше из наиболее часто используемого канала вторичного кэша считываются две четырехсловные строки. Их теги считываются вместе с первой четырехсловной строкой, а теги альтернативного канала читаются одновременно со второй четырехсловной строкой (это осуществляется простым инвертированием старшего разряда адреса).
Страницы: 1, 2, 3, 4, 5, 6, 7, 8, 9
