

 Реферат: Линейные списки. Стек. Дек. Очередь
Реферат: Линейные списки. Стек. Дек. Очередь
Реферат: Линейные списки. Стек. Дек. Очередь
Содержание
Введение 3
Глава 1. Динамические типы данных_ 6
1.1 Списки. Очередь. Стек. Дек. 6
1.2 Динамические информационные структуры_ 22
Глава 2. Разработка факультативного курса «Динамические типы данных»_ 29
2.1 Методические рекомендации по введению факультативного курса в школе_ 29
2.2 Разработка программного средства по теме «Динамические типы данных»_ 38
Заключение 42
Литература_ 44
Приложение 1. (Листинг программы) 45
Введение Сегодня
человек живет в мире, где информация имеет огромное значение. Жизненно важно
научиться правильно с ней работать и использовать различные инструменты для
этой работы. Одним из таких инструментов является компьютер, который стал
универсальным помощником человеку в различных сферах деятельности.
Сегодня
человек живет в мире, где информация имеет огромное значение. Жизненно важно
научиться правильно с ней работать и использовать различные инструменты для
этой работы. Одним из таких инструментов является компьютер, который стал
универсальным помощником человеку в различных сферах деятельности.
В вычислительной машине программы обычно оперируют с таблицами информации. В большинстве случаев это не просто аморфные массы числовых величин: в таблицах присутствуют важные структурные отношения между элементами данных.
Чтобы правильно использовать машину, важно добиться хорошего понимания структурных отношений, существующих между данными, способов представления таковых в машине и методов работы с ними.
Изучить наиболее важные факты, касающиеся информационных структур: их статические и динамические свойства; средства распределения памяти и представления данных; эффективные алгоритмы для создания, изменения, разрушения структурной информации и доступа к ней.
В простейшей форме таблица может быть линейным списком элементов. Тогда присущие ей структурные свойства содержат в себе ответы на такие вопросы, как: "Какой элемент является первым в списке? какой — последним? какой элемент предшествует данному или следует за данным?" Можно много говорить о структуре даже в этом совершенно очевидном случае.
В более сложных ситуациях таблица может быть двумерным массивом (т. е. матрицей, иногда называемой сеткой, имеющей структуру строк и столбцов), либо может быть n-мерным массивом при весьма больших значениях n, либо она может иметь структуру дерева, представляющего отношения иерархии или ветвления, либо это может быть сложная многосвязанная структура с огромным множеством взаимных соединений, такая, например, которую можно найти в человеческом мозгу.
Системы обработки списков полезны в очень многих случаях, однако при их использовании программист нередко сталкивается с излишними ограничениями.
Теперь целесообразно определить несколько терминов и понятий, которыми мы будем часто пользоваться в дальнейшем. Информация в таблице представлена множеством узлов (некоторые авторы называют их "записями", "бусинами", "объектами"); мы иногда вместо "узел" будем говорить "элемент". Каждый узел состоит из одного или нескольких последовательных слов в памяти машины, разделенных на именуемые части, называемые полями. В простейшем случае узел — это просто одно слово памяти, он имеет только одно поле, включающее все слово.
В связи с этим цель нашей работы: Знакомство с теоретическим положением, касающиеся информационных структур и разработка программного средства «Динамические структуры данных».
Этой целью определяется следующая гипотеза: если при изучении данной темы будет использоваться компьютер, то усвоение темы будет более успешным, так как усиливает мотивацию, и влияет на конечный результат.
Предмет исследования: Изучение динамических информационных структур.
Объект исследования: Знакомство учащихся с основами программирования.
Достижением цели и согласно поставленной гипотезы определяются следующие задачи:
1. Изучить литературу по теме динамические информационные структуры, педагогическую и методическую по теме исследования;
2. Проанализировать виды динамических информационных структур;
3. Разработать факультатив по теме исследования;
4. Разработать программный продукт по теме исследования.
Глава 1. Динамические типы данных1.1 Списки. Очередь. Стек. Дек.
Список (list) – набор элементов, расположенных в определенном порядке. Таким набором быть может ряд знаков в слове, слов в предложений в книге. Этот термин может также относиться к набору элементов на диске. Использование при обработке информации списков в качестве типов данных привело к появлению в языках программирования средств обработки списков.
Список очередности (pushup list) – список, в котором последний поступающий элемент добавляется к нижней части списка.
Список с использованием указателей (linked list) – список, в котором каждый элемент содержит указатель на следующий элемент списка.
Линейный список (linear list) — это
множество, состоящее из ![]() узлов
узлов ![]() ,
структурные свойства которого по сути ограничиваются лишь линейным (одномерным)
относительным положением узлов, т. е. теми условиями,
что если
,
структурные свойства которого по сути ограничиваются лишь линейным (одномерным)
относительным положением узлов, т. е. теми условиями,
что если ![]() , то
, то ![]() является первым узлом; если
является первым узлом; если
![]() , то k-му узлу
, то k-му узлу ![]() предшествует
предшествует
![]() и за ним следует
и за ним следует ![]() ;
; ![]() является последним узлом.
является последним узлом.
Операции, которые мы имеем право выполнять с линейными списками, включают, например, следующие:
1. Получить доступ к k-му узлу списка, чтобы проанализировать и/или изменить содержимое его полей.
2. Включить новый узел непосредственно перед k-ым узлом.
3. Исключить k-й узел.
4. Объединить два (или более) линейных списка в один список.
5. Разбить линейный список на два (или более) списка.
6. Сделать копию линейного списка.
7. Определить количество узлов в списке.
8. Выполнить сортировку узлов списка в возрастающем порядке по некоторым полям в узлах.
9. Найти в списке узел с заданным значением в некотором поле.
Специальные случаи k=1 и k=n в операциях (1), (2) и (3) особо выделяются, поскольку в линейном списке проще получить доступ к первому и последнему элементам, чем к произвольному элементу.
В машинных приложениях редко требуются все девять из перечисленных выше операций в самом общем виде. Мы увидим, что имеется много способов представления линейных списков в зависимости от класса операций, которые необходимо выполнять наиболее часто. По-видимому, трудно спроектировать единственный метод представления для линейных списков, при котором все эти операции выполняются эффективно; например, сравнительно трудно эффективно реализовать доступ к k-му узлу в длинном списке для произвольного k, если в то же время мы включаем и исключаем элементы в середине списка. Следовательно, мы будем различать типы линейных списков по главным операциям, которые с ними выполняются.
Очень часто встречаются линейные списки, в которых включение, исключение или доступ к значениям почти всегда производятся в первом или последнем узлах, и мы дадим им специальные названия:
Многие люди поняли важность стеков и очередей и дали другие названия этим структурам; стек называли пуш-даун (push-down) списком, реверсивной памятью, гнездовой памятью, магазином, списком типа LIFO ("last-in-first-out" — "последним включается — первым исключается") и даже употребляется такой термин, как список йо-йо! Очередь иногда называют — циклической памятью или списком типа FIFO ("first-in-first-out" — "первым включается — первым исключается"). В течение многих лет бухгалтеры использовали термины LIFO и FIFO как названия методов при составлении прейскурантов. Еще один термин "архив" применялся к декам с ограниченным выходом, а деки с ограниченным входом называли "перечнями", или "реестрами". Такое разнообразие названий интересно само по себе, Поскольку оно свидетельствует о важности этих понятий. Слова "стек" и "очередь" постепенно становятся стандартными терминами; из всех других словосочетаний, перечисленных выше, лишь "пуш-даун список" остается еще довольно распространенным, особенно в теории автоматов.
При описании алгоритмов, использующих такие структуры, принята специальная терминология; так, мы помещаем элемент на верх стека или снимаем верхний элемент. Внизу стека находится наименее доступный элемент, и он не удаляется до тех пор, пока не будут исключены все другие элементы. Часто говорят, что элемент опускается (push down) в стек или что стек поднимается (pop up), если исключается верхний элемент. Эта терминология берет свое начало от "стеков" закусок, которые можно встретить в кафетериях, или по аналогии с колодами карт в некоторых перфораторных устройствах. Краткость слов "опустить" и "поднять" имеет свое преимущество, но эти термины ошибочно предполагают движение всего списка в памяти машины. Физически, однако, ничего не опускается; элементы просто добавляются сверху, как при стоговании сена или при укладке кипы коробок. В применении к очередям мы говорим о начале и конце очереди; объекты встают в конец очереди и удаляются в момент, когда наконец достигают ее начала. Говоря о деках, мы указываем левый и правый концы. Понятие верха, низа, начала и конца применимо иногда и к декам, если они используются как стеки или очереди. Не существует, однако, каких-либо стандартных соглашений относительно того, где должен быть верх, начало и конец: слева или справа. Таким образом, мы находим, что в наших алгоритмах применимо богатое разнообразие описательных слов: "сверху — вниз" — для стеков, "слева — направо" — для деков и "ожидание в очереди" — для очередей.
Однонаправленный и двунаправленный список – это линейный список, в котором все исключения и добавления происходят в любом месте списка.
Однонаправленный список отличается от двунаправленного списка только связью. То есть в однонаправленном списке можно перемещаться только в одном направлении (из начала в конец), а двунаправленном – в любом. Из рисунка это видно: сверху однонаправленный список, а снизу двунаправленный
![]()
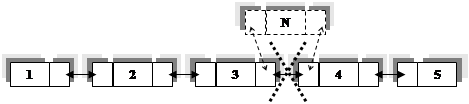 |
На рисунке видно как добавляется и удаляется элемент из двунаправленного списка. При добавлении нового элемента (обозначен N) между элементами 2 и 3. Связь от 3 идет к N, а от N к 4, а связь между 3 и 4 удаляется.
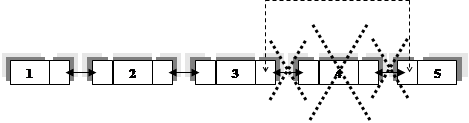 |
В однонаправленном списке структура добавления и удаления такая же только связь между элементами односторонняя.
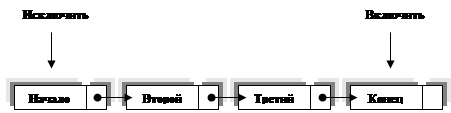
Очередь (queue) — линейный список, в котором все включения производятся на одном конце списка, а все исключения (и обычно всякий доступ) делаются на другом его конце.
Очередь — тип данных, при котором новые данные располагаются следом за существующими в порядке поступления; поступившие первыми данные при этом обрабатываются первыми.
 |
В некоторых разделах математики слово "очередь" используют в более широком смысле, обозначая любой сорт списка, в котором производятся включения и исключения; указанные выше специальные случаи называются тогда "очередями с различными дисциплинами". Однако здесь термин "очередь" используется лишь в узком смысле, аналогичном упорядоченным очередям людей, ожидающим обслуживания.
Правило здесь такое же, как в живой очереди: первым пришёл—первым обслужен. Пришел новый покупатель, встал (добавился) в конец очереди, а который уже отоварился ушел (удалился) из начала очереди. То есть первым пришел, первым ушел.
Другими словами, у очереди есть голова (head) и хвост (tail). Элемент, добавляемый в очередь, оказывается в её хвосте, как только что подошедший покупатель; элемент, удаляемый из очереди, находится в её голове, как тот покупатель, что отстоял дольше всех.
В очереди новый элемент добавляется только с одного конца. Удаление элемента происходит на другом конце. В данном случае это может быть только 4 элемент. Очередь по сути однонаправленный список, только добавление и исключение элементов происходит на концах списка.
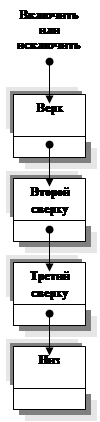
Стек (stack) — линейный список, в котором все включения и исключения (и обычно всякий доступ) делаются в одном конце списка.
 Стек —
часть памяти ОЗУ компьютера, которая предназначается для временного
хранения байтов, используемых микропроцессором; при этом используется порядок
запоминания байтов «последним вошел – первым вышел», поскольку такие ввод и
вывод организовывать проще всего, также операции осуществляются очень быстро.
Действия со стеком производится при помощи регистра указателя стека. Любое
повреждение этой части памяти приводит к фатальному сбою.
Стек —
часть памяти ОЗУ компьютера, которая предназначается для временного
хранения байтов, используемых микропроцессором; при этом используется порядок
запоминания байтов «последним вошел – первым вышел», поскольку такие ввод и
вывод организовывать проще всего, также операции осуществляются очень быстро.
Действия со стеком производится при помощи регистра указателя стека. Любое
повреждение этой части памяти приводит к фатальному сбою.
Стек в виде списка (pushdown list) – стек, организованный таким образом, что последний вводимый в область памяти элемент размещается на вершине списка.
Из стека мы всегда исключаем "младший" элемент из имеющихся в списке, т. е. тот, который был включен позже других. Для очереди справедливо в точности противоположное правило: исключается всегда самый "старший" элемент; узлы покидают список в том порядке, в котором они в него вошли.
Стеки очень часто встречаются в практике. Простым примером может служить ситуация, когда мы просматриваем множество данных и составляем список особых состояний или объектов, которые должны обрабатываться позднее; когда первоначальное множество обработано, мы возвращаемся к этому списку и выполняем последующую обработку, удаляя элементы из списка, пока список не станет пустым. Для этой цели пригодны как стек, так и очередь, но стек, как правило, удобнее. При решении задач наш мозг ведет себя как "стек": одна проблема приводит к другой, а та в свою очередь к следующей; мы накапливаем в стеке эти задачи и подзадачи и удаляем их по мере того, как они решаются. Аналогично процесс входов в подпрограммы и выходов из них при выполнении машинной программы подобен процессу функционирования стека. Стеки особенно полезны при обработке языков, имеющих структуру вложений. К ним относятся языки программирования, арифметические выражения и немецкие "Schachtelsatze" /буквально "вложенные предложения"/. Вообще, стеки чаще всего возникают в связи с алгоритмами, имеющими явно или неявно рекурсивный характер.
