

 Курсовая работа: Дисперсионный анализ
Курсовая работа: Дисперсионный анализ
Гипотеза H0 примет вид σF2 =0. В случае справедливости этой гипотезы
M(S![]() )= M(S
)= M(S![]() )= σ2.
)= σ2.
В случае однофакторного комплекса как для модели I, так и модели II средние квадраты S2 и S2, являются несмещенными и независимыми оценками одной и той же дисперсии σ2.
Следовательно, проверка нулевой гипотезы H0 свелась к проверке существенности различия несмещенных выборочных оценок S![]() и S
и S![]() дисперсии σ2.
дисперсии σ2.
Гипотеза H0 отвергается, если фактически вычисленное значение статистики F =
S![]() /S
/S![]() больше критического Fα:K1:K2, определенного на уровне значимости
α при числе степеней свободы k1=m-1 и k2=mn-m, и принимается, если F < Fα:K1:K2 .
больше критического Fα:K1:K2, определенного на уровне значимости
α при числе степеней свободы k1=m-1 и k2=mn-m, и принимается, если F < Fα:K1:K2 .
F- распределение
Фишера (для x > 0) имеет следующую функцию плотности (для ![]() = 1, 2, ...;
= 1, 2, ...; ![]() = 1, 2, ...):
= 1, 2, ...):
![]()
где ![]() - степени свободы;
- степени свободы;
Г - гамма-функция.
Применительно к данной задаче опровержение гипотезы H0 означает наличие существенных различий в качестве изделий различных партий на рассматриваемом уровне значимости.
Для вычисления сумм квадратов Q1, Q2, Q часто бывает удобно использовать следующие формулы:
 (12)
(12)
 (13)
(13)
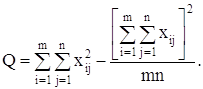 (14)
(14)
т.е. сами средние, вообще говоря, находить не обязательно.
Таким образом, процедура однофакторного дисперсионного анализа состоит в проверке гипотезы H0 о том, что имеется одна группа однородных экспериментальных данных против альтернативы о том, что таких групп больше, чем одна. Под однородностью понимается одинаковость средних значений и дисперсий в любом подмножестве данных. При этом дисперсии могут быть как известны, так и неизвестны заранее. Если имеются основания полагать, что известная или неизвестная дисперсия измерений одинакова по всей совокупности данных, то задача однофакторного дисперсионного анализа сводится к исследованию значимости различия средних в группах данных /1/.
1.3 Многофакторный дисперсионный анализ
Следует сразу же отметить, что принципиальной разницы между многофакторным и однофакторным дисперсионным анализом нет. Многофакторный анализ не меняет общую логику дисперсионного анализа, а лишь несколько усложняет ее, поскольку, кроме учета влияния на зависимую переменную каждого из факторов по отдельности, следует оценивать и их совместное действие. Таким образом, то новое, что вносит в анализ данных многофакторный дисперсионный анализ, касается в основном возможности оценить межфакторное взаимодействие. Тем не менее, по-прежнему остается возможность оценивать влияние каждого фактора в отдельности. В этом смысле процедура многофакторного дисперсионного анализа (в варианте ее компьютерного использования) несомненно более экономична, поскольку всего за один запуск решает сразу две задачи: оценивается влияние каждого из факторов и их взаимодействие /3/.
Общая схема двухфакторного эксперимента, данные которого обрабатываются дисперсионным анализом имеет вид:

Рисунок 1.1 – Схема двухфакторного эксперимента
Данные, подвергаемые многофакторному дисперсионному анализу, часто обозначают в соответствии с количеством факторов и их уровней.
Предположив, что в рассматриваемой задаче о качестве различных m партий изделия изготавливались на разных t станках и требуется выяснить, имеются ли существенные различия в качестве изделий по каждому фактору:
А - партия изделий;
B - станок.
В результате получается переход к задаче двухфакторного дисперсионного анализа.
Все данные представлены в таблице 1.2, в которой по строкам - уровни Ai фактора А, по столбцам — уровни Bj фактора В, а в соответствующих ячейках, таблицы находятся значения показателя качества изделий xijk (i=1,2,...,m; j=1,2,...,l; k=1,2,...,n).
Таблица 1.2 – Показатели качества изделий
|
B1 |
B2 |
… |
Bj |
… |
Bl |
|
|
A1 |
x11l,…,x11k |
x12l,…,x12k |
… |
x1jl,…,x1jk |
… |
x1ll,…,x1lk |
|
A2 |
x21l,…,x21k |
x22l,…,x22k |
… |
x2jl,…,x2jk |
… |
x2ll,…,x2lk |
| … | … | … | … | … | … | … |
|
Ai |
xi1l,…,xi1k |
xi2l,…,xi2k |
… |
xijl,…,xijk |
… |
xjll,…,xjlk |
| … | … | … | … | … | … | … |
|
Am |
xm1l,…,xm1k |
xm2l,…,xm2k |
… |
xmjl,…,xmjk |
… |
xmll,…,xmlk |
Двухфакторная дисперсионная модель имеет вид:
xijk=μ+Fi+Gj+Iij+εijk, (15)
где xijk - значение наблюдения в ячейке ij с номером k;
μ - общая средняя;
Fi - эффект, обусловленный влиянием i-го уровня фактора А;
Gj - эффект, обусловленный влиянием j-го уровня фактора В;
Iij - эффект, обусловленный взаимодействием двух факторов, т.е. отклонение от средней по наблюдениям в ячейке ij от суммы первых трех слагаемых в модели (15);
εijk - возмущение, обусловленное вариацией переменной внутри отдельной ячейки.
Предполагается, что εijk имеет нормальный закон распределения N(0; с2), а все математические ожидания F*, G*, Ii*, I*j равны нулю.
Групповые средние находятся по формулам:
- в ячейке:
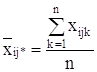 ,
,
по строке:
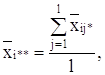
по столбцу:
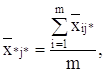
общая средняя:
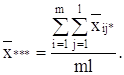
В таблице 1.3 представлен общий вид вычисления значений, с помощью дисперсионного анализа.
Таблица 1.3 – Базовая таблица дисперсионного анализа
| Компоненты дисперсии | Сумма квадратов | Число степеней свободы | Средние квадраты |
| Межгрупповая (фактор А) |
|
m-1 |
|
| Межгрупповая (фактор B) |
|
l-1 |
|
| Взаимодействие |
|
(m-1)(l-1) |
|
| Остаточная |
|
mln - ml |
|
| Общая |
|
mln - 1 |
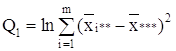
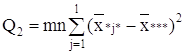
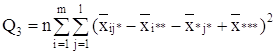
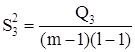
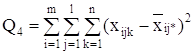
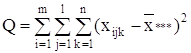
Проверка нулевых
гипотез HA, HB, HAB об отсутствии влияния на рассматриваемую переменную
факторов А, B и их взаимодействия AB осуществляется сравнением отношений ![]() ,
, ![]() ,
, ![]() (для модели I с
фиксированными уровнями факторов) или отношений
(для модели I с
фиксированными уровнями факторов) или отношений ![]() ,
, ![]() ,
, ![]() (для случайной модели II) с
соответствующими табличными значениями F – критерия Фишера – Снедекора. Для
смешанной модели III проверка гипотез относительно факторов с фиксированными
уровнями производится также как и в модели II, а факторов со случайными
уровнями – как в модели I.
(для случайной модели II) с
соответствующими табличными значениями F – критерия Фишера – Снедекора. Для
смешанной модели III проверка гипотез относительно факторов с фиксированными
уровнями производится также как и в модели II, а факторов со случайными
уровнями – как в модели I.
Если n=1, т.е.
при одном наблюдении в ячейке, то не все нулевые гипотезы могут быть проверены
так как выпадает компонента Q3 из общей суммы квадратов отклонений, а с ней и
средний квадрат ![]() , так как в этом случае не может
быть речи о взаимодействии факторов.
, так как в этом случае не может
быть речи о взаимодействии факторов.
С точки зрения техники вычислений для нахождения сумм квадратов Q1, Q2, Q3, Q4, Q целесообразнее использовать формулы:

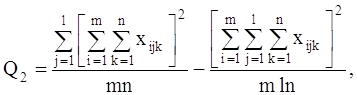
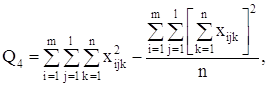
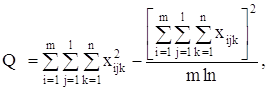
Q3 = Q – Q1 – Q2 – Q4.
Отклонение от основных предпосылок дисперсионного анализа — нормальности распределения исследуемой переменной и равенства дисперсий в ячейках (если оно не чрезмерное) — не сказывается существенно на результатах дисперсионного анализа при равном числе наблюдений в ячейках, но может быть очень чувствительно при неравном их числе. Кроме того, при неравном числе наблюдений в ячейках резко возрастает сложность аппарата дисперсионного анализа. Поэтому рекомендуется планировать схему с равным числом наблюдений в ячейках, а если встречаются недостающие данные, то возмещать их средними значениями других наблюдений в ячейках. При этом, однако, искусственно введенные недостающие данные не следует учитывать при подсчете числа степеней свободы /1/.
2 Применение дисперсионного анализа в различных процессах и исследованиях
2.1 Использование дисперсионного анализа при изучении миграционных процессов
Миграция - сложное социальное явление, во многом определяющее экономическую и политическую стороны жизни общества. Исследование миграционных процессов связано с выявлением факторов заинтересованности, удовлетворенности условиями труда, и оценкой влияния полученных факторов на межгрупповое движение населения.
λij=ciqijaj,
где λij – интенсивность переходов из исходной группы i (выхода) в новую j (входа);
ci – возможность и способности покинуть группу i (ci≥0);
qij – привлекательность новой группы по сравнению с исходной (0≤qij≤1);
aj – доступность группы j (aj≥0).
Если считать численность группы i равной ni, то оценкой случайной величины νij - числа переходов из i в j – будет niciqijaj:
νij≈ niλij=niciqijaj. (16)
На практике для отдельного человека вероятность p перехода в другую группу мала, а численность рассматриваемой группы n велика. В этом случае действует закон редких событий, то есть пределом νij является распределение Пуассона с параметром μ=np:
![]() .
.
С ростом μ распределение приближается к нормальному. Преобразованную же величину √νij можно считать нормально распределенной.
Если прологарифмировать выражение (16) и сделать необходимые замены переменных, то можно получить модель дисперсионного анализа:
ln√νij=½lnνij=½(lnni+lnci+lnqij+lnaj)+εij,
Xi,j=2ln√νij-lnni-lnqij,
Ci=lnci,
Aj=lnaj,
Xi,j=Ci+Aj+ε.
Значения Ci и Aj позволяют получить модель двухфакторного дисперсионного анализа с одним наблюдением в клетке. Обратным преобразованием из Ci и Aj вычисляются коэффициенты ci и aj.
При проведении дисперсионного анализа в качестве значений результативного признака Y следует взять величины:
Yij=Xi,j-X,
Х=(Х1,1+Х1,2+:+Хmi,mj)/mimj,
где mimj- оценка математического ожидания Хi,j;
Хmi и Хmj - соответственно количество групп выхода и входа.
Уровнями фактора I будут mi групп выхода, уровнями фактора J - mj групп входа. Предполагается mi=mj=m. Встает задача проверки гипотез HI и HJ о равенствах математических ожиданий величины Y при уровнях Ii и при уровнях Jj, i,j=1,…,m. Проверка гипотезы HI основывается на сравнении величин несмещенных оценок дисперсии sI2 и so2. Если гипотеза HI верна, то величина F(I)= sI 2/so2 имеет распределение Фишера с числами степеней свободы k1=m-1 и k2=(m-1)(m-1). Для заданного уровня значимости α находится правосторонняя критическая точка xпр,αкр. Если числовое значение F(I)чис величины попадает в интервал (xпр,αкр, +∞), то гипотеза HI отвергается и считается, что фактор I влияет на результативный признак. Степень этого влияния по результатам наблюдений измеряется выборочным коэффициентом детерминации, который показывает, какая доля дисперсии результативного признака в выборке обусловлена влиянием на него фактора I. Если же F(I)чис<xпр,αкр, то гипотеза HI не отвергаются и считаются, что влияние фактора I не подтвердилось. Аналогично проверяется гипотеза HJ о влиянии фактора J /4/.
2.2 Принципы математико-статистического анализа данных медико-биологических исследований
В зависимости от поставленной задачи, объема и характера материала, вида данных и их связей находится выбор методов математической обработки на этапах как предварительного (для оценки характера распределения в исследуемой выборке), так и окончательного анализа в соответствии с целями исследования. Крайне важным аспектом является проверка однородности выбранных групп наблюдения, в том числе контрольных, что может быть проведено или экспертным путем, или методами многомерной статистики (например, с помощью кластерного анализа). Но первым этапом является составление вопросника, в котором предусматривается стандартизованное описание признаков. В особенности при проведении эпидемиологических исследований, где необходимо единство в понимании и описании одних и тех же симптомов разными врачами, включая учет диапазонов их изменений (степени выраженности). В случае существенности различий в регистрации исходных данных (субъективная оценка характера патологических проявлений различными специалистами) и невозможности их приведения к единому виду на этапе сбора информации, может быть затем осуществлена так называемая коррекция ковариант, которая предполагает нормализацию переменных, т.е. устранение ненормальностей показателей в матрице данных. "Согласование мнений" осуществляется с учетом специальности и опыта врачей, что позволяет затем сравнивать полученные ими результаты обследования между собой. Для этого могут использоваться многомерный дисперсионный и регрессионный анализы.
